리플리케이션
on 조잘조잘
목차
리플리케이션 적용기
들어가기전…
안녕하세요, 피카입니다. 기존 주절주절에는 단일 DB로 데이터를 저장하고 조회하는 방식을 처리했습니다. 해당 DB 구조는 일반적으로 간단한 프로젝트에서 자주 사용하는 구조입니다. 하지만 이러한 구조는 다음과 같은 문제가 있습니다.
- 하나의 DB로 쓰기와 조회를 동시에 처리하게 됩니다.
- DB 장애시 DB를 사용하는 모든 기능 동작이 멈추게 됩니다.
- 하나의 DB가 모든 부하를 감당하게 됩니다.
이러한 문제는 하나의 DB를 사용하기 때문에 생기는 문제입니다. 현재 주절주절 트래픽에서 리플리케이션을 적용할만큼의 성능 이슈가 일어나지 않습니다. 하지만 리플리케이션은 트래픽 뿐만 아닌, 단일 장애점 방지, 백업의 이유도 있습니다. 이러한 이유로 주절주절에 리플리케이션을 적용하기로 결정해였습니다.
리플리케이션은 다음과 같은 장점이 있습니다.
- 스케일 아웃: 여러 대의 DB를 늘려 성능 처리의 향상을 꾀할 수 있습니다.
- 데이터 백업: 다수의 DB에 데이터를 동기화시켜 저장해놓기 때문에 데이터 백업이 자연스럽게 됩니다.
- 단일 장애점 방지: 여러 대의 Replica DB를 두기 때문에 하나의 Replica DB가 고장나도 기능을 수행할 수 있습니다.
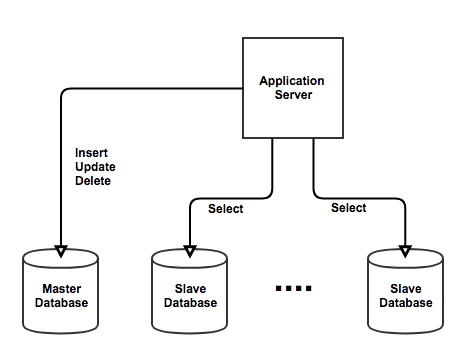
프로젝트에 적용한 구조는 하나의 Source(source Database)와 두 개의 Replica(Replica Database)로 구성되어 있습니다.
각 데이터 베이스는 MySql 8.0.27을 사용하였습니다.
기본 환경은 ubuntu 18.04 입니다.
Mysql 설치
주절주절에서는 mysql 8.0버전을 사용합니다.
기존 mysql을 설치할 경우 5.7버전을 그대로 설치하므로 8.0을 설치하기 위해 다른 명령어를 입력해야합니다.
//apt를 업데이트 하기 위한 데이터를 받아온다.
sudo wget https://dev.mysql.com/get/mysql-apt-config_0.8.15-1_all.deb
sudo dpkg -i mysql-apt-config_0.8.15-1_all.deb
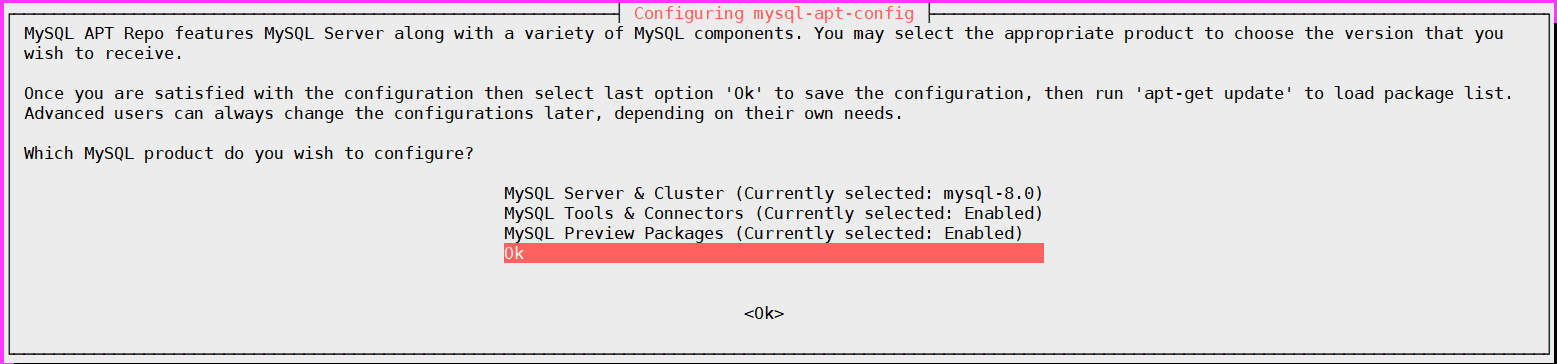
OK를 선택해줍니다.
//위에서 다운로드 받은 데이터를 기반으로 업데이트한다.
sudo apt-get update
//8.0버전을 설치한다.
sudo apt-get install mysql-server
설치를 마치면 비밀번호를 입력하는 창으로 넘어갑니다. 비밀번호를 입력합니다.

mysql 설치가 완료가 됩니다. 다음 명령어를 통해 mysql에 접속합니다.
mysql 실행
sudo mysql -u root -p
mysql 설정
기본적으로 리플리케이션은 source와 replica 두가지 DB로 나뉩니다. 따라서 각각 설정을 해주어야합니다.
mysql source db 설정
/etc/mysql/mysql.conf.d/mysqld.cnf파일을 열어 server-id와 log_bin 파일을 설정해줍니다. (source)
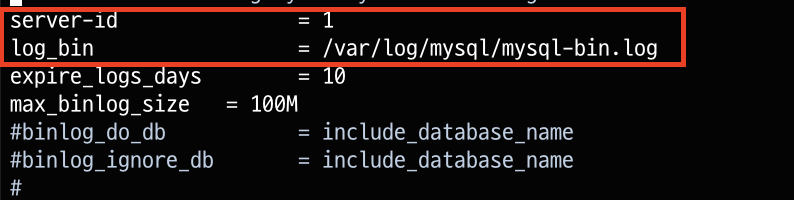
server-id(1~2^32-1 범위)는 개별 db서버를 인식하는데 사용되며 기본 값은 0입니다. source db는 1, replica-1는 2, replica-2는 3…과 같은 방식으로 구별합니다.
mysql은 bin_log 파일을 통해 source 진행된 상황을 replica 읽어 동기화를 합니다. 따라서 log_bin 파일의 위치를 설정해주어야합니다.
기본적으로 모든 데이터베이스를 리플리케이션하지만 binlog_do_db를 설정해주면 해당 데이터베이스만을 리플리케이션합니다. 만약 추가로 데이터 베이스를 추가하고 싶다면 binlog_do_db를 계속 추가해주면 됩니다. (ignore은 제외시킬 데이터베이스)
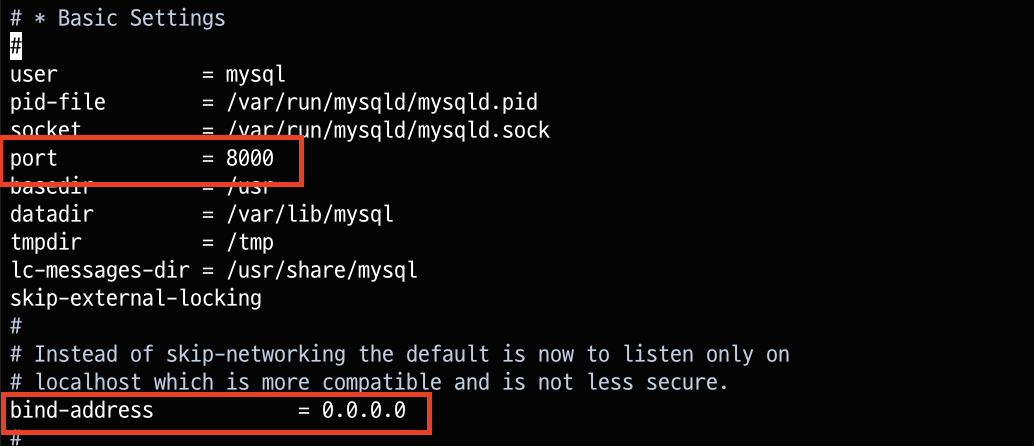
참고: 현재 우아한테크코스에서 제공해주는 AWS는 보안상의 이유로 몇몇 포트를 막아놓았습니다. 따라서 기본 포트를 8000번으로 바꾸어주고 mysql에서 외부접속을 허용하도록 bind-address를 0.0.0.0으로 변경해주어야합니다.
- 설정을 적용시키기 위해 mysql을 다시 시작합니다. (source)
$ sudo service mysql restart
- 데이터 베이스를 만들어줍니다.

- 각 리플리케이션은 사용자 계정을 통해 연결되므로 사용자를 만들어 주어야합니다. (source)
참고:
'userid'@'%'에서'%'는 외부에서 접근을 허용
mysql> CREATE USER 'repl'@'%.example.com' IDENTIFIED BY 'password';

- 해당 계정에 모든 권한을 줘도 됩니다. 만약 불안하다면 replication 권한만 줄 수 있습니다. (source) ```sql mysql> GRANT REPLICATION SLAVE ON . TO ‘repl’@’%.example.com’;
// 권한 적용 mysql> flush privileges;

> 참고: replication 권한을 설정할 때 {database}.* 으로 설정하게되면 `SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT, CREATE USER` 옵션은 글로벌 옵션이기 때문에 *.* 전체 타깃으로만 사용이 가능하다.

6. source db 정보를 확인합니다. (source)
```sql
mysql> show master status;
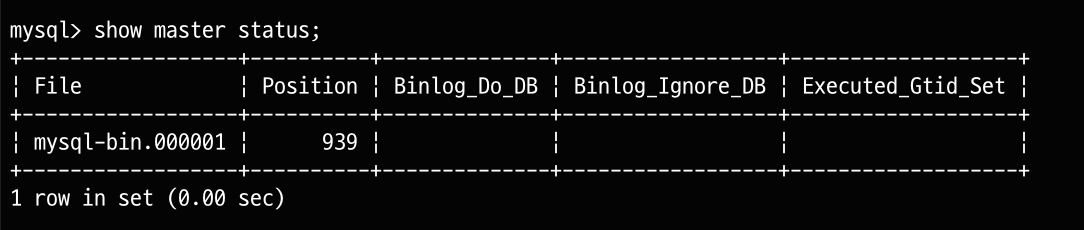
File(mysql-bin.000001)과 Position(939)를 기억해야합니다. 이 정보는 후에 replica 설정할 때 사용합니다.
각각은 로그 파일의 이름과 파일내의 위치를 나타냅니다. 자세한 정보는 공식 문서 binary log 를 통해 확인할 수 있습니다.
mysql replica db 설정
/etc/mysql/mysql.conf.d/mysqld.cnf파일을 열어 server-id를 설정해줍니다. (replica)
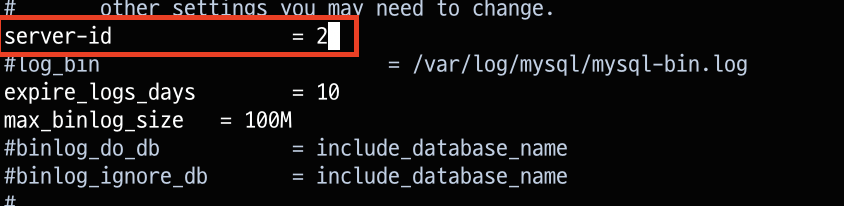
- 설정을 적용시키기 위해 mysql을 다시 시작합니다. (replica)
$ sudo service mysql restart
- 데이터 베이스를 만들어줍니다. (replica)

- Replica와 source DB를 연결합니다. (replica)
mysql> change master to
-> master_host={master_db_ip},
-> master_port={master_db_port},
-> master_user={master_username},
-> master_password={master_password},
-> master_log_file={master_bin_file},
-> master_log_pos={position};

- replica를 실행 해줍니다. (replica)
mysql> start slave;
show slave status\G; 명령어를 치면 replica 상태와 source 연결 정보를 확인할 수 있습니다.
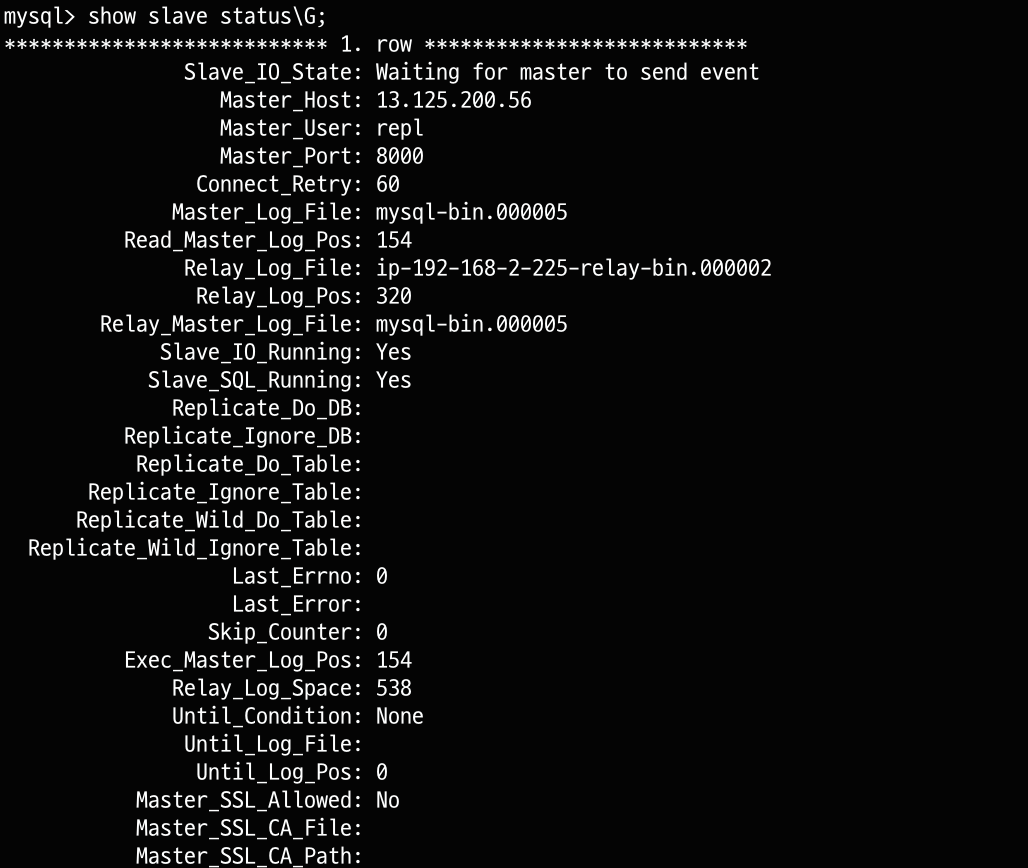
Slave_IO_State가 Waiting for master to send event 상태가 되어야 합니다.
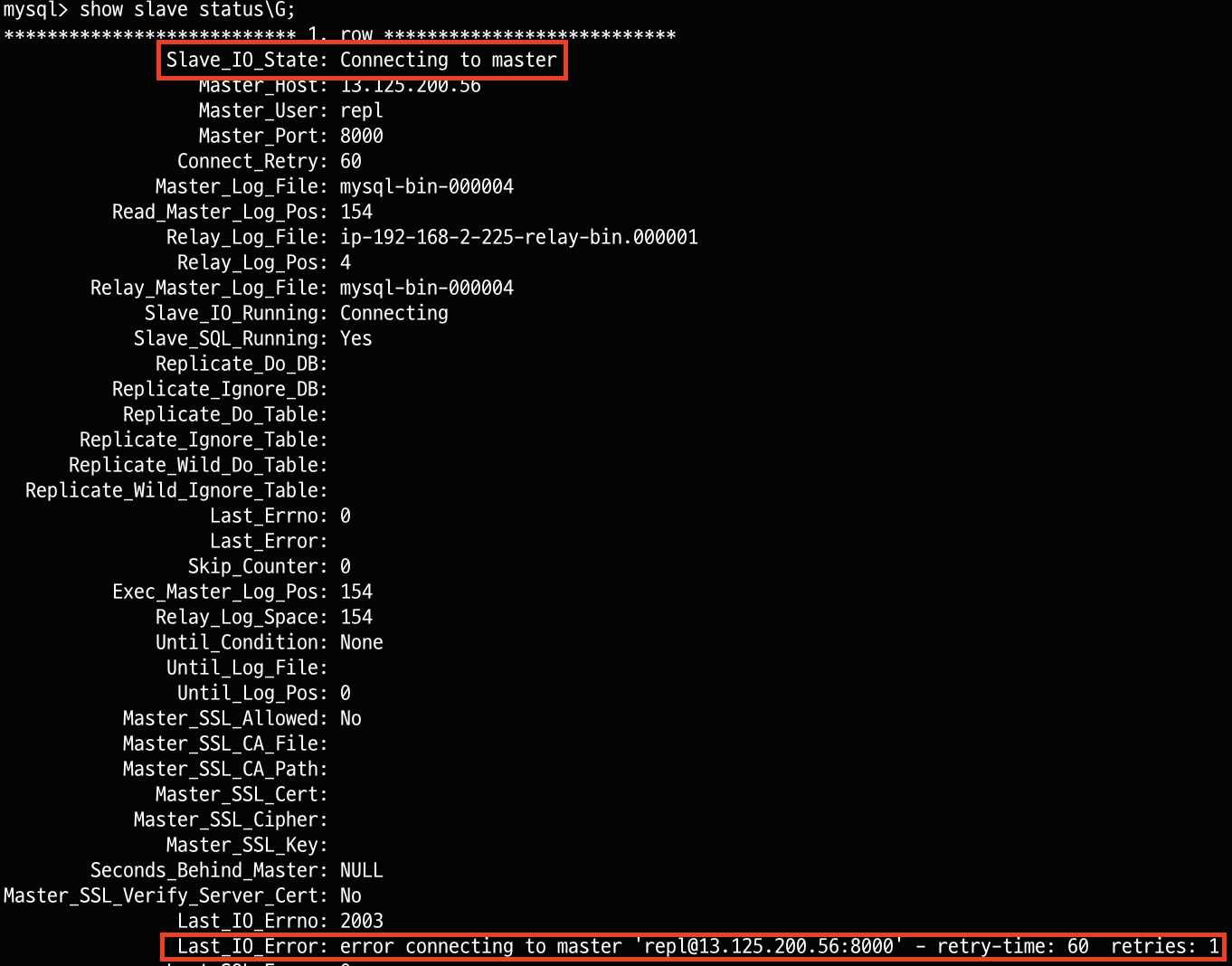
error connecting to master 에러가 뜰 경우 참고
error connecting to master 'repl@13.125.200.56:8000' - retry-time: 60 retries: 1와 같은 에러 메시지가 뜰 수 있습니다. 이럴 경우 source 서버에 접근하지 못하는 상태입니다. 따라서 source 서버에 접근할 수 있도록 ip나 포트를 제대로 설정해주어야합니다.
프로세스 확인
각각 source와 replica mysql에 show processlist\G; 명령어를 통해 프로세스로 연결되어있는 것을 확인할 수 있습니다.
source
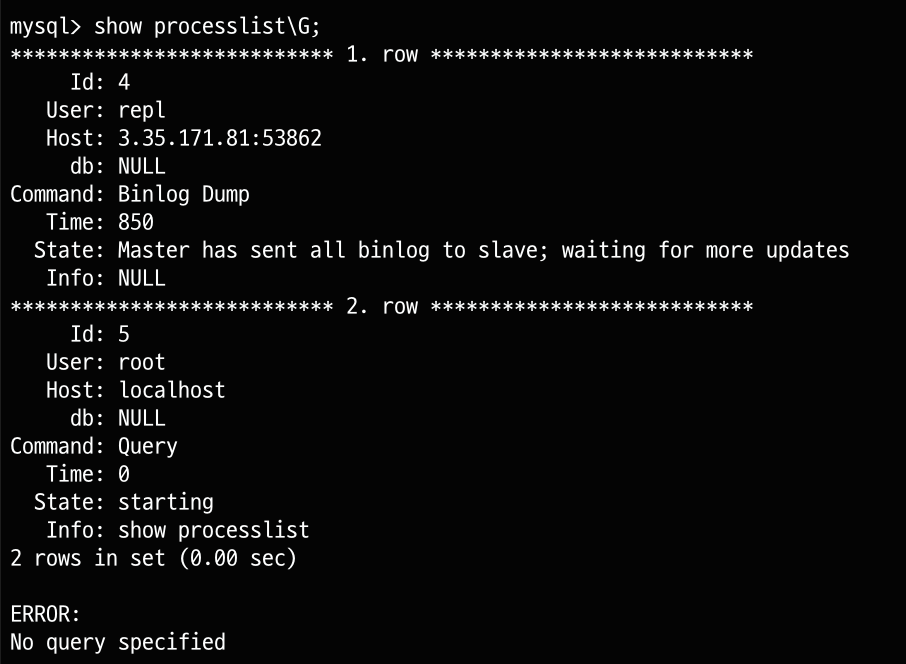
replica
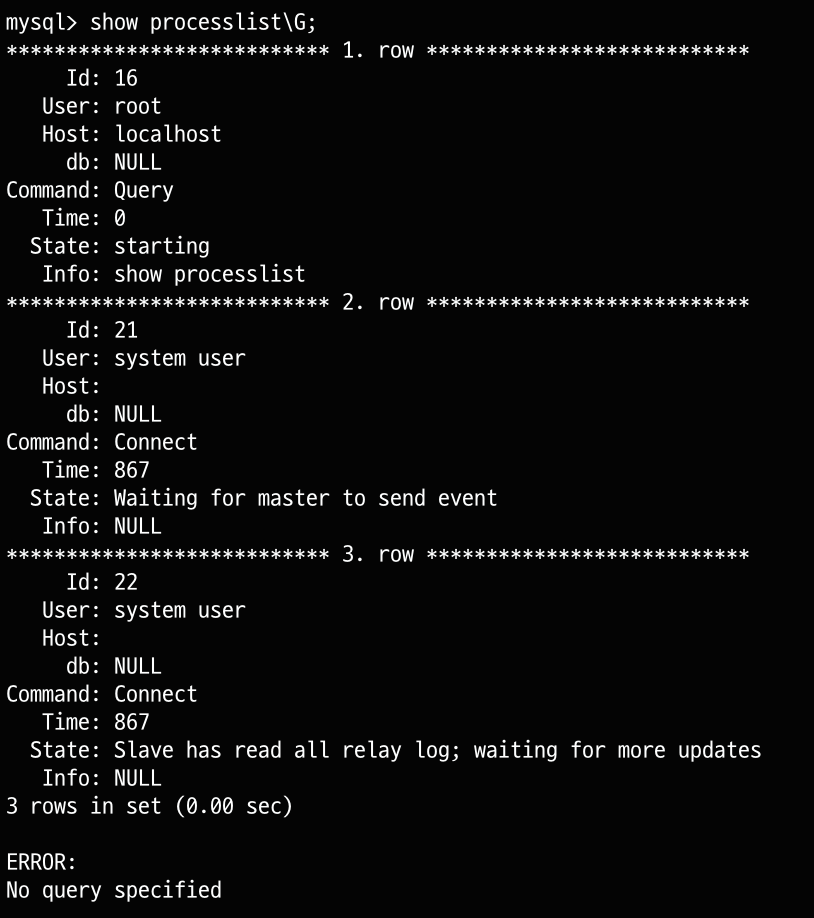
테스트 확인
실제 source DB에 테이블을 만들고 값을 넣게 되면 replica DB에 값이 들어가는 것을 확인할 수 있습니다.
source DB
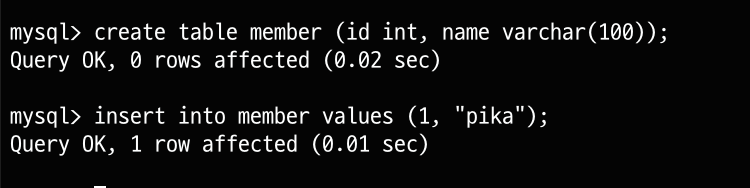
replica DB
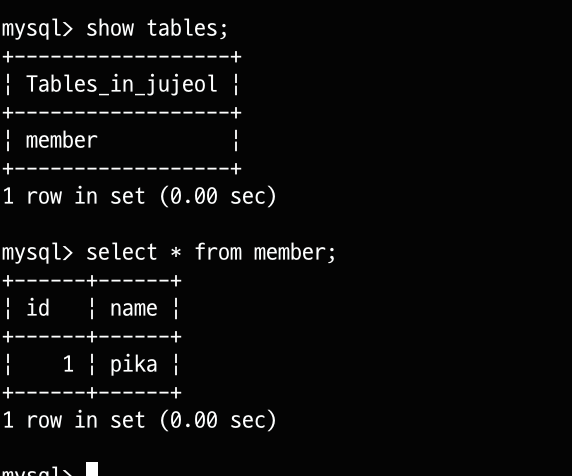
source DB에 member 테이블과 (1, pika) 데이터를 넣었을 때, replica DB에도 같이 적용되는 것을 확인할 수 있습니다.
Spring Boot 설정
application.yml 설정
datatsource가 여러개이기 때문에 자동 설정을 사용할 수 없다 따라서 application.yml 또는 application.properties에 사용할 DB 정보를 설정해줍니다.
spring:
config:
activate:
on-profile: prod
jpa:
database: mysql
database-platform: org.hibernate.dialect.MySQL8Dialect
properties:
hibernate:
show_sql: true
format_sql: true
use_sql_comments: true
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://source_ip주소:3306/jujeol?useSSL=true
username:
password:
replica1:
url: jdbc:mysql://replica1_ip주소:3306/jujeol?useSSL=true
username:
password:
replica2:
url: jdbc:mysql://replica2_ip주소:3306/jujeol?useSSL=true
username:
password:
yml 정보 객체 바인딩
CustomDataSourceProperties.java
@Getter
@Setter
@ConfigurationProperties(prefix = "spring.datasource")
public class CustomDataSourceProperties {
private final Replica replica1 = new Replica();
private final Replica replica2 = new Replica();
private String name = "source";
private String url;
private String username;
private String password;
@Getter
@Setter
public static class Replica {
private String name;
private String url;
private String username;
private String password;
}
}
앞서 yml에 설정한 정보는 사용자 임의로 정의해준 형식이기 때문에 해당 정보를 java 코드로 사용할 수 있도록 ConfigurationProperties를 사용하여 바인딩해주어야합니다. 해당 어노테이션은 내부적으로 getter, setter를 사용하므로 필수적으로 getter, setter 메서드가 있어야합니다.
Datasource 등록
자동으로 Datasource를 등록해주었던 이전과는 다르게 등록해줘야할 Datasource가 여러개이므로 수동으로 등록해주어야합니다.
@Configuration
@EnableAutoConfiguration(exclude = {DataSourceAutoConfiguration.class}) // 자동 등록 제외
@EnableConfigurationProperties(CustomDataSourceProperties.class)
public class DatasourceConfig {
private static final String MYSQL_JDBC_DRIVER = "com.mysql.cj.jdbc.Driver";
private final CustomDataSourceProperties databaseProperty;
public DatasourceConfig(CustomDataSourceProperties databaseProperty) {
this.databaseProperty = databaseProperty;
}
}
@EnableAutoConfiguration(exclude = {DataSourceAutoConfiguration.class})으로 기존에 자동으로 설정하는 부분을 제외해줍니다.
@EnableConfigurationProperties(CustomDataSourceProperties.class)으로 CustomDatasource를 등록해줍니다.
Source Replica 분기처리
public class ReplicationRoutingDataSource extends AbstractRoutingDataSource {
private boolean replicaSelector = false;
@Override
protected Object determineCurrentLookupKey() {
boolean isReadOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
if (isReadOnly) {
DatabaseReplicaType replicaType = chooseNextReplica();
log.info("Select replica DB : {}", replicaType);
return replicaType;
} else {
log.info("Select source DB : {}", SOURCE);
return SOURCE;
}
}
private DatabaseReplicaType chooseNextReplica(){
replicaSelector = !replicaSelector;
return replicaSelector ? REPLICA1 : REPLICA2;
}
}
@Transactional(readOnly=true)인 경우 replica datasource로, 나머지는 source datasource로 분기 처리를 하기위한 ReplicationRoutingDataSource 클래스를 생성합니다.
determineCurrentLookupKey()메서드는 현재 요청에서 사용할 datasource의 key값을 반환해줍니다.
chooseNextReplica에서 boolean값을 통해 어떤 replica를 사용할지 정해집니다. 현재는 2개의 DB만 사용하고 있어 boolean 값을 사용하였지만 추후 3개 이상의 DB를 사용할 경우 다른 방법으로 구현해야할 것입니다. 이렇게 한 이유는 circular 방식으로 할 경우 thread safe하지 않아 에러가 날 수 있기 때문입니다.
실제로 돌려보게되면 50대 50으로 정확히 나오지는 않고 오차가 어느정도 있지만 감안할 정도입니다.

DataSourceConfig 구현
@Configuration
@EnableAutoConfiguration(exclude = {DataSourceAutoConfiguration.class})
@EnableConfigurationProperties(CustomDataSourceProperties.class)
public class DatasourceConfig {
private static final String MYSQL_JDBC_DRIVER = "com.mysql.cj.jdbc.Driver";
private final CustomDataSourceProperties databaseProperty;
public DatasourceConfig(CustomDataSourceProperties databaseProperty) {
this.databaseProperty = databaseProperty;
}
@Primary
@Bean
public DataSource dataSource() {
return new LazyConnectionDataSourceProxy(routingDataSource());
}
@Bean
public DataSource routingDataSource() {
Map<Object, Object> dataSources = createDataSources(databaseProperty);
ReplicationRoutingDataSource replicationRoutingDataSource = new ReplicationRoutingDataSource();
replicationRoutingDataSource.setDefaultTargetDataSource(dataSources.get(SOURCE));
replicationRoutingDataSource.setTargetDataSources(dataSources);
return replicationRoutingDataSource;
}
private Map<Object, Object> createDataSources(CustomDataSourceProperties databaseProperty) {
Map<Object, Object> dataSourceMap = new LinkedHashMap<>();
dataSourceMap.put(SOURCE,
createDataSource(databaseProperty.getUrl(),
databaseProperty.getUsername(),
databaseProperty.getPassword())
);
dataSourceMap.put(REPLICA1,
createDataSource(databaseProperty.getReplica1().getUrl(),
databaseProperty.getReplica1().getUsername(),
databaseProperty.getReplica2().getPassword())
);
dataSourceMap.put(REPLICA2,
createDataSource(databaseProperty.getReplica2().getUrl(),
databaseProperty.getReplica2().getUsername(),
databaseProperty.getReplica2().getPassword())
);
return dataSourceMap;
}
public DataSource createDataSource(String url, String username, String password) {
return DataSourceBuilder.create()
.type(HikariDataSource.class)
.url(url)
.driverClassName(MYSQL_JDBC_DRIVER)
.username(username)
.password(password)
.build();
}
}
LazyConnectionDataSourceProxy를 사용하는 이유
일반적으로 Spring에서는 DataSource를 하나만 사용하기 때문에 시작전에 정해 놓습니다. 그러나 리플렉션을 사용할 경우 DataSource가 아직 정해지지 않았으므로 Lazy 전략을 사용하여 실제 쿼리가 실행 될 때 DataSource를 가져옵니다.
네이밍(카멜 케이스? 언더바?)
DataSourceAutoConfiguration를 사용하지 않기 때문에 자동으로 설정되던 부분이 빠졌습니다. 그 중 하나가 네이밍인데 자동 설정을 했을 경우 언더바를 자동으로 붙여주지만 그렇지 않을 경우 카멜케이스로 네이밍을 하게 됩니다. 따라서 프로퍼티 설정에 spring.jpa.properties.hibernate:physical_naming_strategy: org.springframework.boot.orm.jpa.hibernate.SpringPhysicalNamingStrategy을 설정해주어야합니다.