Elasticsearch - 1편
on 조잘조잘
검색엔진과 검색시스템
대부분의 서비스에 빠지지 않는 검색 기능. 이 기능을 부르는 용어로는 검색엔진, 검색 시스템, 검색 서비스 등이 대표적이다. 엘라스틱서치에 알아보기 전에 이 용어들의 정의를 먼저 살펴보자.
검색엔진(search engine)은 웹에서 정보를 수집해 검색 결과를 제공하는 프로그램이다. 검색 시스템(search system)은 대용량 데이터 기반으로 신뢰성 있는 검색 결과를 제공하기 위해 검색엔진을 기반으로 구축된 시스템을 뜻한다. 검색 서비스(search service)는 검색 시스템을 활용해 검색 결과를 서비스로 제공하는 것을 뜻한다.
검색 서비스 > 검색 시스템 > 검색엔진
엘라스틱서치는 엄밀히 말하면 검색엔진이며 검색 서비스를 제공하기 위해 엘라스틱서치를 이용해 검색 시스템을 구축한다고 생각하면 될 거 같다.
엘라스틱서치란?
Elastic 홈페이지에서는 Elasticsearch를 Elastic Stack의 심장이라고 소개하고 있는 만큼 Elasticsearch는 전체 스택의 중심이며 가장 중요한 역할을 하고 있다. 기본적으로 모든 데이터를 색인하여 저장하고 검색, 집계 등을 수행하며 결과를 클라이언트 또는 다른 프로그램으로 전달하여 동작하게 한다.
특징
- 오픈소스 (open source)
- 자바 기반인 루씬으로 만들어진 오픈 소스 프로젝트
- 준 실시간 분석 (Near-Real Time)
- 전문(full text) 검색 엔진
- 루씬은 기본적으로 역파일 색인(inverted file index)라는 구조로 데이터를 저장
- 이렇게 가공된 텍스트를 검색하는 것을 전문(full text) 검색이라고 한다.
- RESTFul API
- 모든 데이터 조회, 입력, 삭제 등을 http 프로토콜을 이용한 Rest API로 처리
기본 용어 정리
- [동사] 색인 (indexing) : 데이터가 검색될 수 있는 구조로 변경하기 위해 원본 문서를 검색어 토큰들으로 변환하여 저장하는 일련의 과정이다.
- [명사] 인덱스 (index, indices) : 색인 과정을 거친 결과물, 또는 색인된 데이터가 저장되는 저장소. 또한 Elasticsearch에서 도큐먼트들의 논리적인 집합을 표현하는 단위이기도 하다.
- 검색 (search) : 인덱스에 들어있는 검색어 토큰들을 포함하고 있는 문서를 찾아가는 과정.
- 질의 (query) : 사용자가 원하는 문서를 찾거나 집계 결과를 출력하기 위해 검색 시 입력하는 검색어 또는 검색 조건.
RDBMS와 차이점
왜 검색을 기존 RDBMS로 하지 않고 검색엔진을 이용할까? 그것은 RDBMS의 한계와 연관이 깊다.
데이터베이스는 데이터를 통합 관리하는 데이터의 집합이고 저장 방식에 따라 관계형 또는 계층형으로 나뉜다. SQL문을 이용해 원하는 정보의 검색이 가능하지만 텍스트 매칭을 통한 단순한 검색만 가능하고 여러 단어로 변형, 동의어나 유의어를 활용한 검색이 불가능하다.
이와 다르게 검색엔진은 데이터베이스에서 불가능한 비정형 데이터를 색인하고 검색할 수 있다. 형태소 분석을 통해 자연어의 처리도 가능하고 역색인 구조를 바탕으로 빠른 검색 속도도 보장한다.
| RDBMS | Elasticsearch |
|---|---|
| 정형 데이터 | 비정형 데이터 |
| 텍스트 매칭을 통해 단순 검색 | 전문 검색을 통해 정확한 검색 |
| 유의어, 동의어 불가능 | 유의어, 동의어 가능 |
엘라스틱서치 설치
Elasticsearch는 https://www.elastic.co/downloads/elasticsearch 에서 설치 가능하다.
EC2에서 엘라스틱서치를 사용하므로 리눅스 버전을 다운받았다.
Elasticsearch 실행을 위해서는 자바1.8 이상의 버전이 설치되어 있어야 하며 JAVA_HOME 환경변수가 잡혀있어야 한다. 각 버전 별로 필요한 자바 버전은 ttps://www.elastic.co/support/matrix#matrix_jvm 페이지에서 확인이 가능하다.
Elasticsearch 7.0 버전부터는 기본 배포판에 open-jdk 가 포함되어 있어 따로 Java를 설치 해 주지 않아도 된다. 대신 운영체제에 맞게 배포판을 받아야 한다.
엘라스틱서치 환경 설정
Elasticsearch는 각 노드들 별로 실행될 설정들을 각각 적용함으로써 노드들의 역할을 나누거나 클러스터의 속성을 결정하게 된다. Elasticsearch 의 실행 환경을 설정하는 방법은 홈 디렉토리의 config 경로 아래 있는 파일들을 변경하거나 시작 명령으로 설정하는 방법이 있는데 나는 config 아래에 있는 파일을 변경하는 방법을 이용했다.
- jvm.options - Java 힙메모리 및 환경변수
- elasticsearch.yml - Elasticsearch 옵션
- log4j2.properties - 로그 관련 옵션
vi config/jvm.options
-Xms1g
-Xmx1g
7.0 기준으로 1gb의 힙메모리가 기본으로 설정. 원하는 값으로 변경 가능
node-1 ec2 기준(각 노드별로 각각 설정 적용해야 함)
vi config/elasticsearch.yml
cluster.name: "es-cluster-1"
node.name: "node-1"
network.host: ["_local_", "_site_"]
discovery.seed_hosts: ["elastic-1", "elastic-2", "elastic-3"]
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
http.port: 9000
transport.port: 8888
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.keystore.path: certs/es-cluster.p12
xpack.security.transport.ssl.truststore.path: certs/es-cluster.p12
_local_ : 로컬 IP
_site_ : private IP
discovery.seed_hosts : 클러스터 구성을 위해 바인딩 할 원격 노드들의 IP
cluster.initial_master_nodes : 클러스터가 최초 실행 될 때 해당 노드들 중에서 마스터 노드 선출
http.port : http 통신을 할 port
transport.port : 노드들 간 tcp 통신을 할 port
xpack : 보안 관련 설정들. 추후 설명하겠습니다.
각 노드 인스턴스마다 /etc/hosts에 노드들의 private IP 등록
192.168.1.212 elastic-1
192.168.1.224 elastic-2
192.168.1.206 elastic-3
호스트 별칭 설정한다고 생각하면 된다. 이 설정을 통해 이름으로 IP 설정 가능.
/etc/security/limits.conf 에 아래 내용 추가
elasticsearch - nofile 65535
max file descriptors를 기존 4096에서 65535로 늘려줘야한다. 설정을 변경하지 않으면 실행 시 에러가 발생.
virtual memory 설정
/etc/sysctl.conf에 아래 내용 추가
vm.max_map_count=262144
기존 map count는 너무 적어 262144로 변경한다.
보안 설정
config/elasticsearch.yml 에 추가
xpack.security.enabled: true
이를 통해 보안 기능 활성화가 된다.
이 설정만 추가하고 엘라스틱서치를 실행하면 에러가 발생한다.
보안 기능만 활성화 하고 어떤 보안을 하는지 없기 때문에 에러가 뜨는 거라 하나하나 설정해보자.
xpack.security.transport.ssl.enabled: true
이 설정을 해주고 공개키랑 대칭키를 입력을 해줘야 한다. 먼저 키를 만들어주자.
bin/elasticsearch-certutil ca 를 입력하면 아래와 같은 화면이 뜬다.
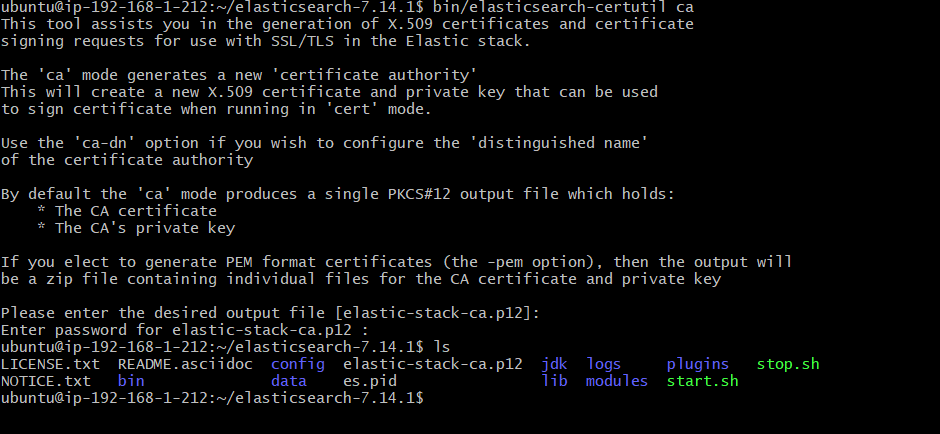
엔터를 누르고 비밀번호를 설정해주자. 그러면 공개키가 생성된다.
그 다음 config 아래 certs 라는 폴더를 만들어주자.
mkdir config/certs
그리고
./bin/elasticsearch-certutil cert \
--ca elastic-stack-ca.p12 \
--dns elastic-1,elastic-2,elastic-3 \
--ip 192.168.1.212,192.168.1.224,192.168.1.206 \
--out config/certs/es-cluster.p12
//dns, ip들 사이에 띄어쓰기 넣으면 오류납니다.
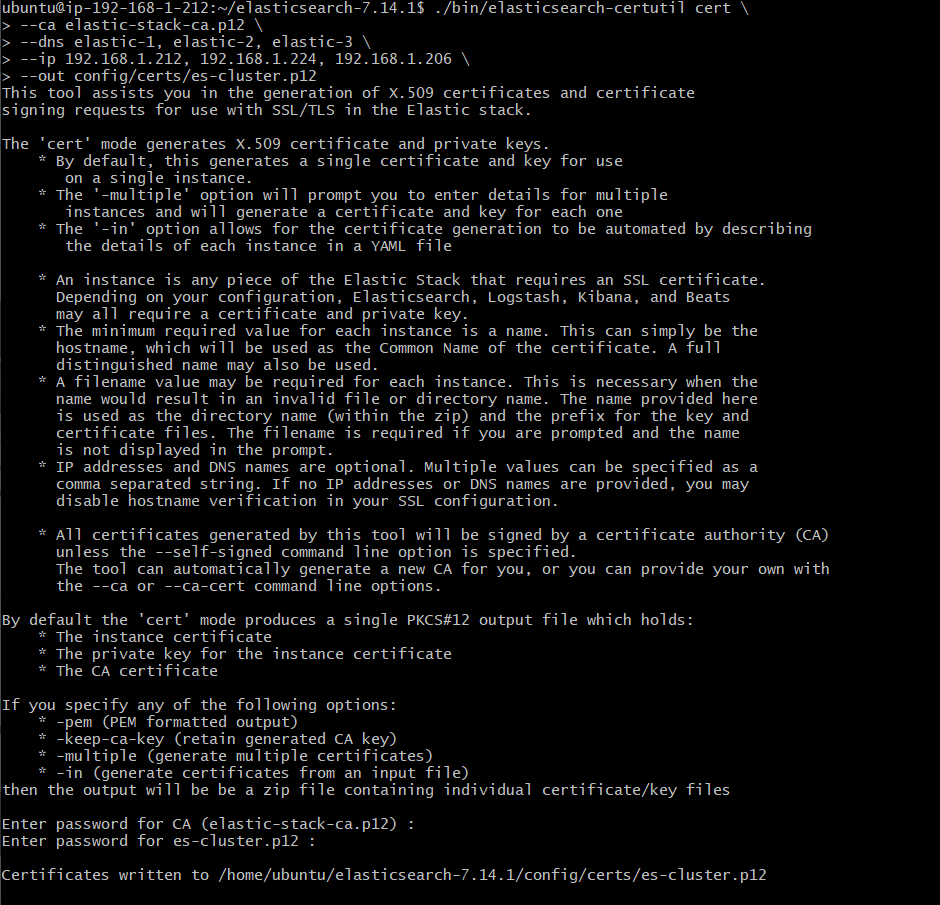
비밀번호 동일하게 설정했습니다.
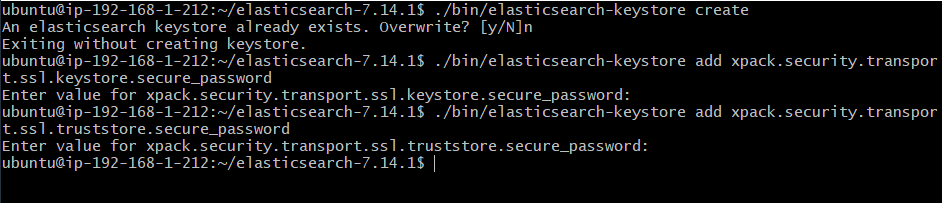
./bin/elasticsearch-keystore create
./bin/elasticsearch-keystore add xpack.security.transport.ssl.keystore.secure_password
./bin/elasticsearch-keystore add xpack.security.transport.ssl.truststore.secure_password
한 줄씩 입력하면서 위 이미지와 같이 비밀번호 설정하면 된다.
설정을 마치면 아까 생성한 config/certs에 es-cluster.p12란 이름으로 인증서가 생성되었다.
이렇게 생성된 인증서를 다른 노드에도 추가해줘야 합니다.
1번 노드에 생성한 인증서를 로컬로 복사

로컬에 있는 인증서를 2,3번 노드에 복사
config/elasticsearch.yml에 인증서 추가
xpack.security.transport.ssl.keystore.path: certs/es-cluster.p12
xpack.security.transport.ssl.truststore.path: certs/es-cluster.p12
config/elasticsearch.yml 최종 설정
cluster.name: "es-cluster-1"
node.name: "node-1"
network.host: ["_local_", "_site_"]
discovery.seed_hosts: ["elastic-1", "elastic-2", "elastic-3"]
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
http.port: 9000
transport.port: 8888
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.keystore.path: certs/es-cluster.p12
xpack.security.transport.ssl.truststore.path: certs/es-cluster.p12
이로써 기본 환경설정은 끝이 났다. 엘라스틱서치를 실행시켜보자.
start.sh 작성
bin/elasticsearch -d -p es.pid
-p 옵션으로 Process ID 저장
stop.sh 작성
kill `cat es.pid`
chmod 755 "*.sh" 를 통해 둘 다 권한을 준다.
저장된 Process ID를 통해 간단하게 kill 시킨다.
각 노드별로 start.sh를 실행시키면 엘라스틱서치가 작동된다.
이제 키바나를 설치해서 시각화 작업을 하자.
키바나
나는 node-3 인스턴스에 키바나를 설치했다.
config/kibana.yml에 설정
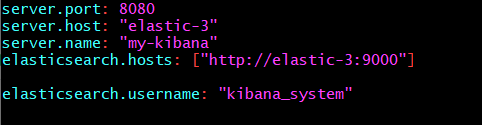
기존 port는 5601. 프로젝트 보안 상 열려있는 port 중에 5601이 없기 때문에 8080으로 할당했다.
엘라스틱서치에 유저와 비밀번호를 설정했기 때문에 이를 키바나에도 적용해야 한다.

bin/kibana-keystore create
bin/kibana-keystore add elasticsearch.password
위 이미지와 같이 비밀번호를 설정했다.
키바나는 nodejs 기반이다.
cat package.json에 들어가보면 node : “14.17.5” 버전이 나와있음
먼저 nvm을 설치한다.
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.0/install.sh | bash
그 후 nvm을 통해 동일 버전 nodejs 다운로드
pm2 설치
npm install pm2 -g
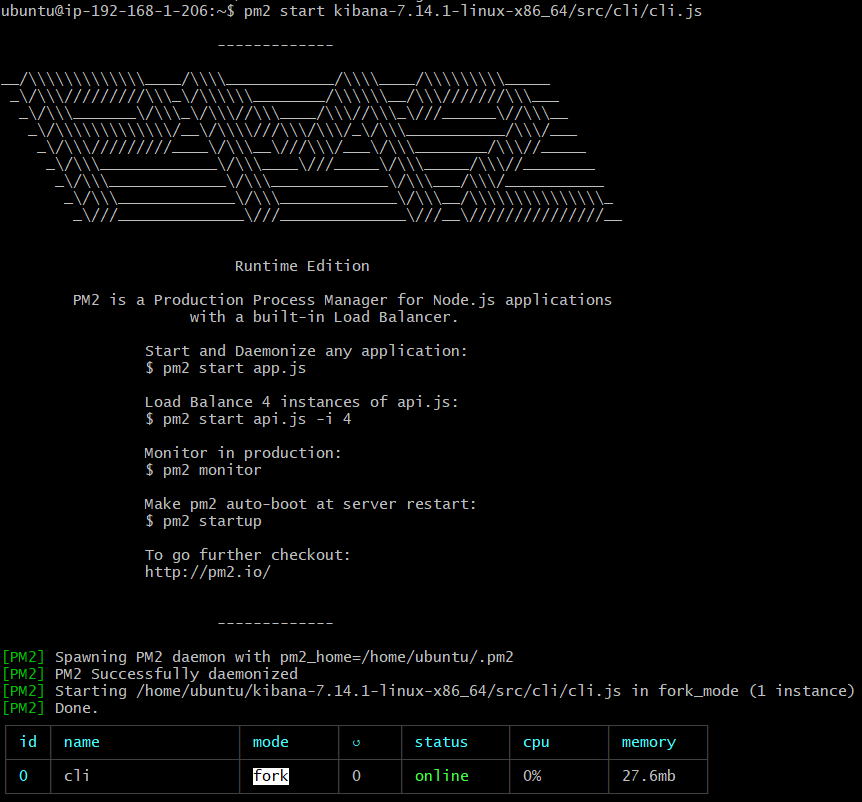
start.sh 작성
pm2 start kibana-7.14.1-linux-x86_64/src/cli/cli.js --name kibana //이름 변경
stop.sh 작성
pm2 stop [app이름]
start.sh를 실행시킨 후 설정에서 server.host에 설정한 IP:port에 접속해서 이름과 비밀번호를 치면 키바나 메인화면으로 간다.
검색(Search)
키바나에 접속해서 devtools로 가면 아래와 같은 화면을 볼 수 있다.
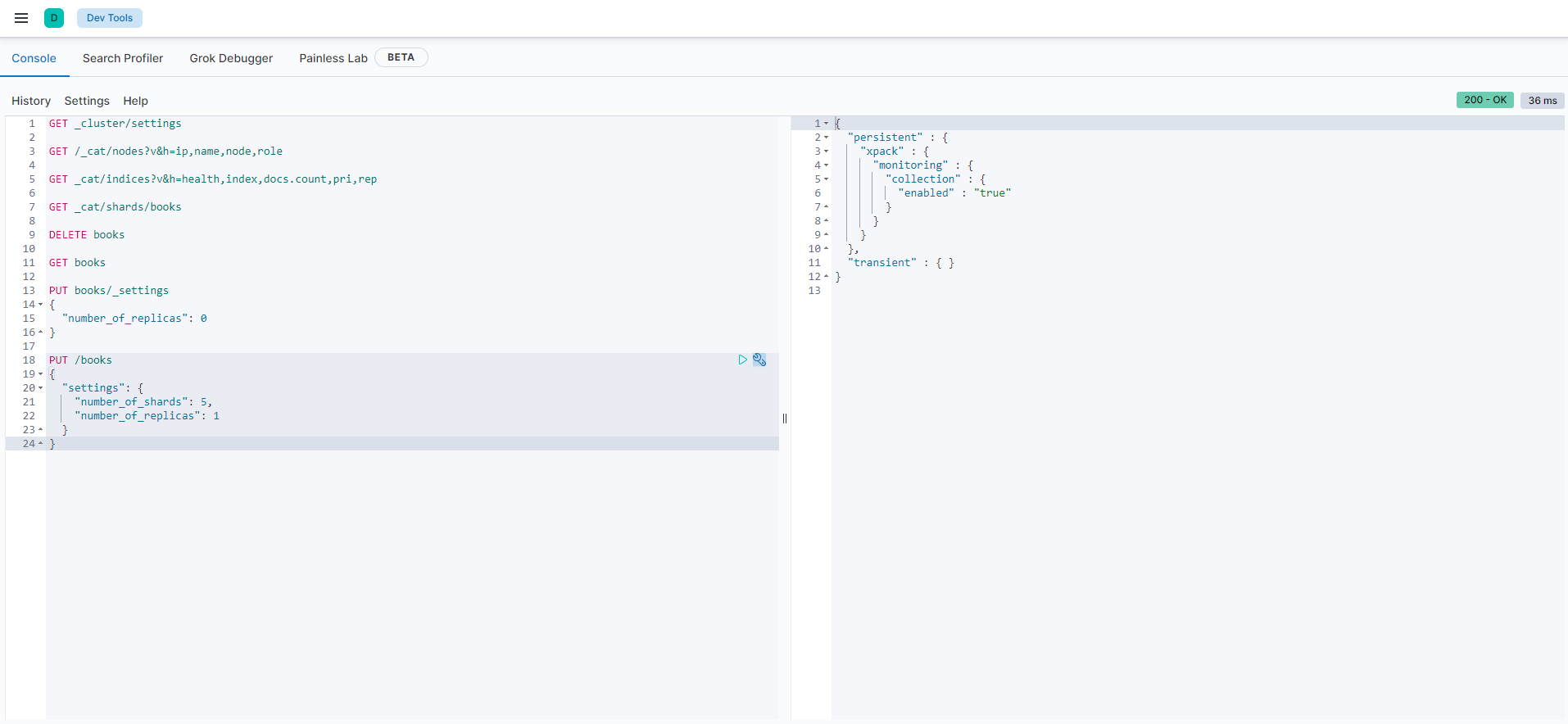
이제 드디어 검색을 위한 환경을 마련했다. 먼저 비교를 통해 RDBMS의 용어 개념과 연관지어보자.
| RDBMS | Elasticsearch |
|---|---|
| 데이터베이스 | 인덱스 |
| 파티션 | 샤드 |
| 테이블 | 타입 |
| 컬럼 | 필드 |
| 행 | 도큐먼트 |
인덱스 설정
RDBMS에서 database를 설정하듯 인덱스를 설정해보자.
PUT drink
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
샤드의 개수를 3개로 정하고 복제본이 1개인 설정을 가진 drink 인덱스가 생성되었다.
- 샤드 : 루씬의 단일 검색 인스턴스로 인덱스는 샤드 단위로 분리되어 각 노드에 분산 저장됨.
현재는 노드당 하나의 샤드가 들어가도록 3개로 설정했다.
분석기 설정
분석기가 있어야 우리가 원하는 형태의 색인이 가능하다. 정리, 색인할 때 특정한 규칙과 흐름에 의해 텍스트를 변경(토큰화)하는 과정을 분석(Analyze)이라고 하며, 해당 처리는 분석기(Analyzer)를 통해서 이루어진다. 프로젝트에선 한글명과 영문명 두 개의 필드를 비교하므로 각각 다른 분석기가 필요하다. 영어명 필드는 snowball 형태소 분석기를 사용하고 한글명 필드는 nori라는 토크나이저를 사용했다.
프로젝트 인덱스 세팅
PUT drink
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
,
"analysis": {
"analyzer": {
"english_name_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lowercase", "stop", "snowball"]
}
,
"nori_without_category_analyzer": {
"type": "custom",
"tokenizer": "nori_mixed",
"filter": ["nori_filter", "category_stop_filter"]
}
,
"nori_with_category_analyzer": {
"type": "custom",
"tokenizer": "nori_mixed",
"filter": ["nori_filter"]
}
}
,
"tokenizer": {
"nori_mixed": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
}
}
,
"filter": {
"nori_filter": {
"type": "nori_part_of_speech",
"stoptags": [
"IC"
]
}
,
"category_stop_filter": {
"type": "stop",
"stopwords": [
"소주", "맥주", "와인", "막걸리", "양주", "칵테일"
]
}
}
}
}
,
"mappings": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "text",
"analyzer": "nori_without_category_analyzer"
},
"englishName": {
"type": "text",
"analyzer": "english_name_analyzer"
},
"category": {
"type": "text",
"analyzer": "nori_with_category_analyzer"
}
}
}
}
검색 쿼리
GET drink/_search
{
"query": {
"bool": {
"should": [
{
"match_phrase": {
"name": {
"query": "금성맥주",
"slop": 1,
"boost": 2
}
}
}
,
{
"match_phrase": {
"englishName": {
"query": "금성맥주",
"slop": 1,
"boost": 2
}
}
}
,
{
"multi_match" : {
"query": "금성맥주",
"type": "best_fields",
"fields": ["name", "englishName"],
"tie_breaker": 0.3
}
}
,
{
"match": {
"category": {
"query": "금성맥주",
"boost": 0.5
}
}
}
]
}
}
}
bool 복합 쿼리를 사용했다. 여러 조건들을 총합해서 검색하는 쿼리로 must, must_not, should, filter 가 있다. 자세한 설명은 아래 참고 자료 Elastic 가이드 북에 있다. 나는 원하는 조건을 맞추기 위해 위에서부터 조건에 맞으면 가중치를 주고 없으면 다음 조건으로 넘어가는 should를 사용했다. must일 시 조건에 해당하지 않으면 false를 반환해버려 A가 아니면 B라는 조건이 성립하지 않는다. 따로 or 조건을 걸어줄 수도 있지만 가중치 boost를 통해 score 조절을 해서 원하는 결과에 가까울수록 점수가 높아지도록 하고 싶었기 때문에 should를 사용했다.
다음 편에서는 이것을 자바 코드에서 어떻게 이용하는지 알아보자.