인덱스
on 조잘조잘
목차
인덱스
인덱스 개념
인덱스
추가적인 저장 공간을 활용하여 DB 테이블의 검색 속도를 향상시키기 위한 자료구조
일반적으로 DB에서 데이터를 검색할 경우, 전체 테이블을 스캔(Full Table Scan)하기 때문에 데이터가 많아지게 될 경우, 조회시 느릴 수 밖에 없다. 이를 개선하기 위해 나온 기법이 인덱스 이다.

인덱스는 흔히 접할 수 있는 책에서도 찾아볼 수 있다. 그림처럼 책에 인덱스가 없다면 우리는 원하는 내용을 앞에서부터 하나하나 살펴보며 찾아야할 것이다. 데이터 베이스도 마찬가지이다. 대용량 데이터에서 원하는 데이터를 빠르게 조회하기 위해 인덱스를 사용한다.
인덱스 구조
대부분의 DBMS는 인덱스 구조로 B-Tree를 사용하고 있다. B-Tree를 사용하는 이유는 데이터베이스 인덱스는 왜 ‘B-Tree’를 선택하였는가 글을 읽어보면 좋을 것 같다.
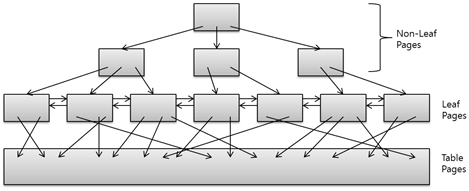
출처: https://d2.naver.com/helloworld/1155
B-Tree 인덱스는 Root - Branch - Leaf 구조로 되어있다.
- Root & Branch
- 하위 노드의 주소와 Data 범위 키 값을 가지고 있다.
- Leaf
- 인덱스 키값, Table Block 주소, 앞 뒤 Index Block 주소를 가지고 있다.
클러스터 vs 넌클러스터
클러스터
특징
- 테이블당 1개씩만 허용한다.
- 리프 노드 == 데이터 페이지
- 데이터가 정렬되어있다.
- 넌클러스터에 비해 조회 속도가 빠르지만 입력, 수정, 삭제는 느리다.
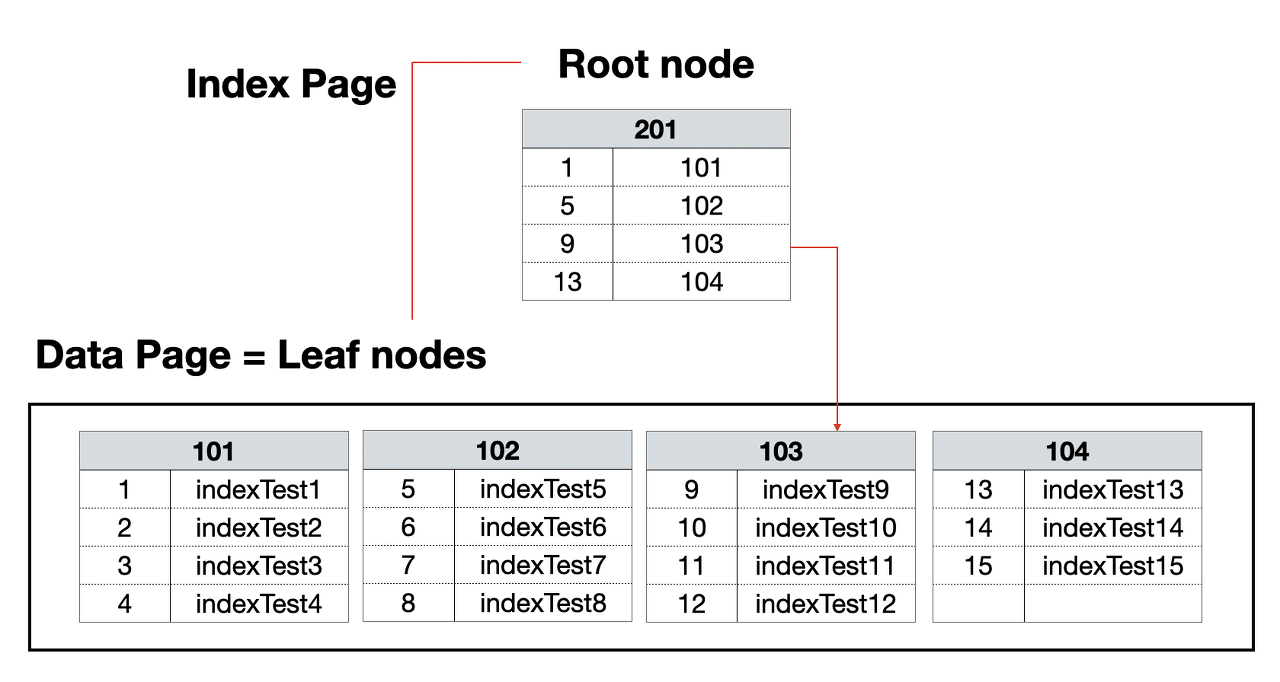 출처; https://junghn.tistory.com/entry/DB-%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0-%EC%9D%B8%EB%8D%B1%EC%8A%A4%EC%99%80-%EB%84%8C%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0-%EC%9D%B8%EB%8D%B1%EC%8A%A4-%EA%B0%9C%EB%85%90-%EC%B4%9D%EC%A0%95%EB%A6%AC
출처; https://junghn.tistory.com/entry/DB-%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0-%EC%9D%B8%EB%8D%B1%EC%8A%A4%EC%99%80-%EB%84%8C%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0-%EC%9D%B8%EB%8D%B1%EC%8A%A4-%EA%B0%9C%EB%85%90-%EC%B4%9D%EC%A0%95%EB%A6%AC
그림으로 보는 것처럼 데이터 페이지와 리프 노드가 같은 것을 확인할 수 있다.
넌클러스터
특징
- 테이블에 여러개가 존재할 수 있다.
- 인덱스와 데이터 페이지가 따로 존재한다.
- 리프 노드가 실제 데이터가 있는 주소값을 가진다.
- 데이터 페이지는 따로 정렬되어있지 않다.
- 클러스터에 비해 조회 속도는 느리지만 입력, 수정, 삭제가 빠르다.
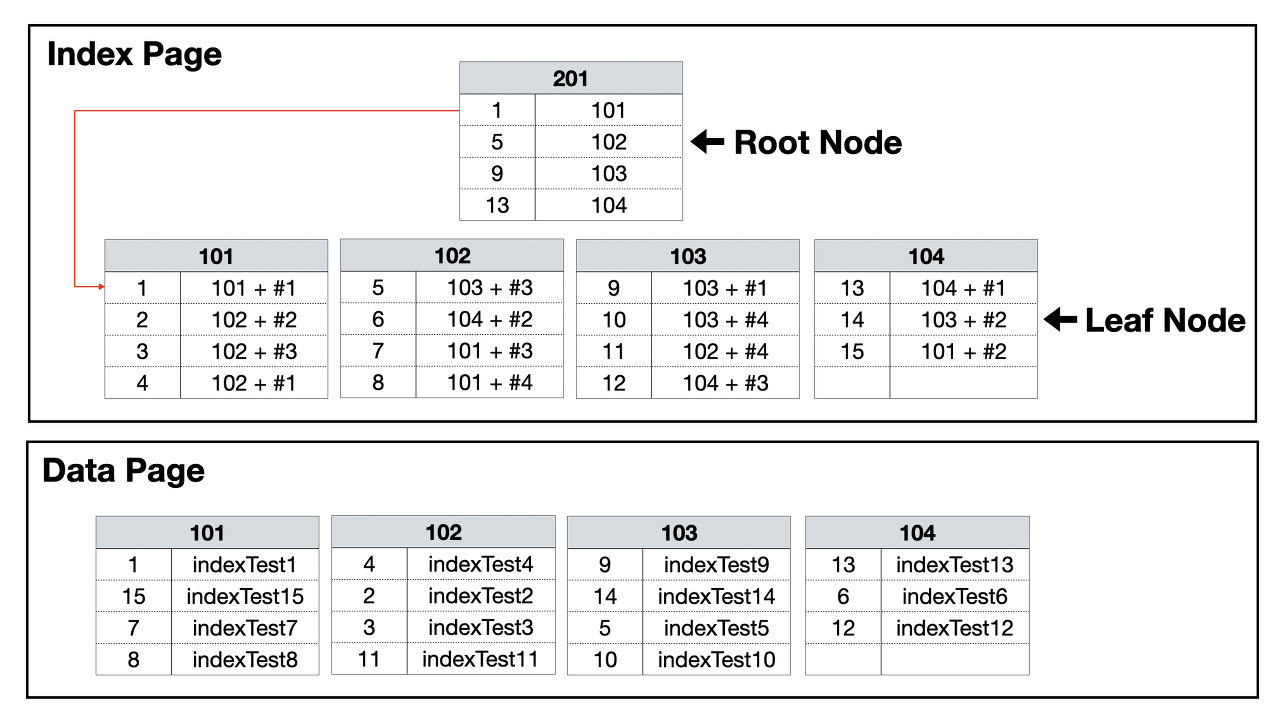 출처; https://junghn.tistory.com/entry/DB-%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0-%EC%9D%B8%EB%8D%B1%EC%8A%A4%EC%99%80-%EB%84%8C%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0-%EC%9D%B8%EB%8D%B1%EC%8A%A4-%EA%B0%9C%EB%85%90-%EC%B4%9D%EC%A0%95%EB%A6%AC
출처; https://junghn.tistory.com/entry/DB-%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0-%EC%9D%B8%EB%8D%B1%EC%8A%A4%EC%99%80-%EB%84%8C%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0-%EC%9D%B8%EB%8D%B1%EC%8A%A4-%EA%B0%9C%EB%85%90-%EC%B4%9D%EC%A0%95%EB%A6%AC
넌클러스터 인덱스는 데이터 페이지 와 인덱스 페이지 가 분리되어있는 것을 볼 수 있다. 인덱스 페이지는 해당 데이터를 찾아가기 위한 주소(포인터)만을 가지고 있다. 데이터가 추가 될때는 실제 값이 데이터 페이지에 정렬되지 않은 상태로 추가되며, 그 위치는 인덱스 페이지에 저장된다.
인덱스 탐색
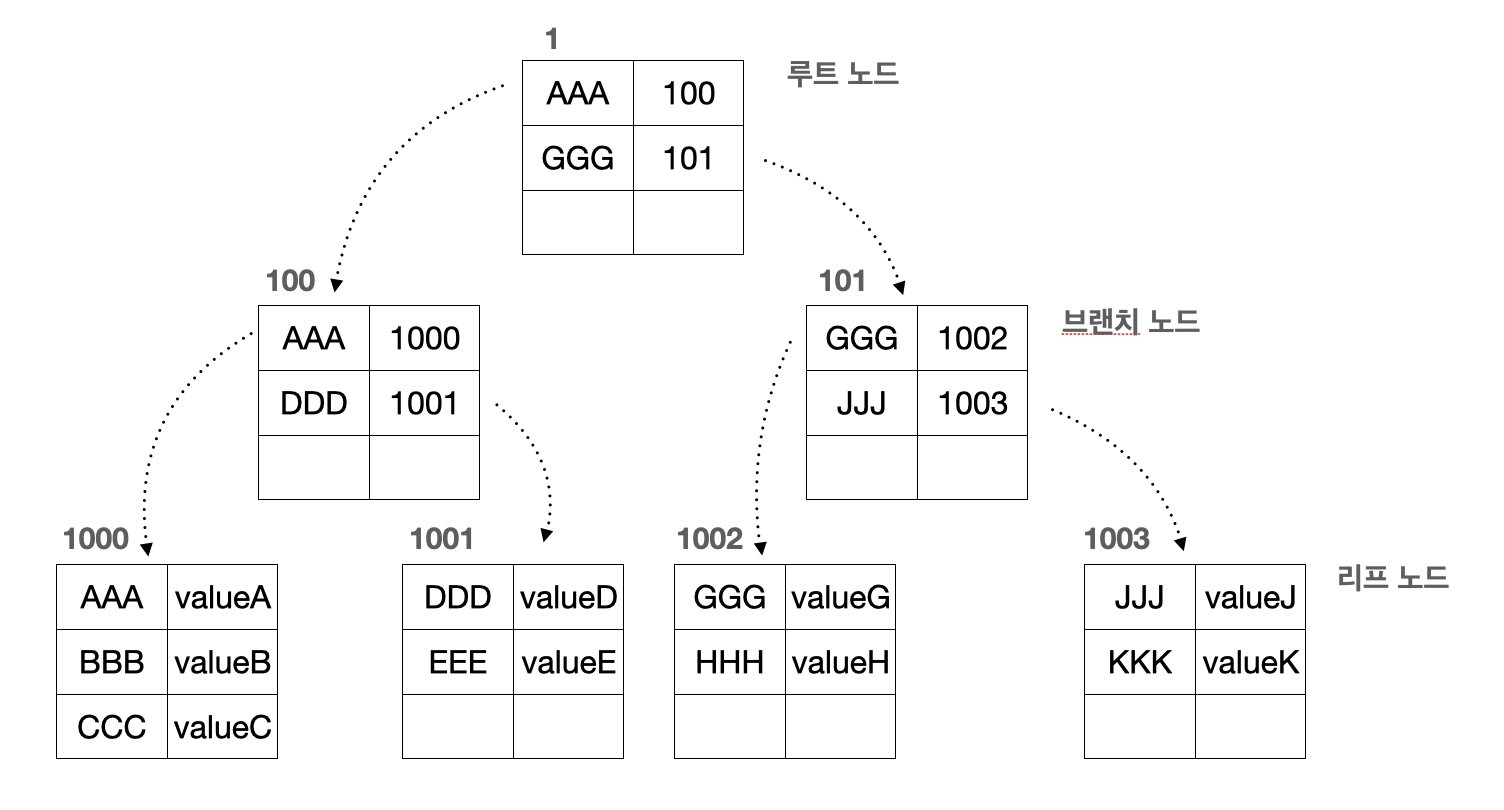
간단한 클러스터 인덱스 구조를 예시로 들어 탐색 과정을 설명하겠다.
만약 HHH라는 값을 탐색하고자 하자.
기존 DB 방식에서는 AAA, BBB, CCC, DDD, EEE, GGG, HHH 총 7번의 탐색 과정을 거치게 될 것이다.
인덱스 구조에서는 루트 노드(1번 테이블) -> 브랜치 노드(101번 테이블) -> 리프노드(1002번) -> 1002번내 테이블 검색(2번째 value) 총 4번의 탐색 과정을 거친다.
현재는 3번의 차이밖에 나지 않지만 데이터가 더 쌓일 경우 많은 차이를 보이게 될 것이다.
인덱스 조회 과정은 이런 순서로 이루어지게된다. 인덱스 추가 삭제 과정은 찰리의 인덱싱에서 확인할 수 있다.
인덱스 칼럼 기준
인덱스를 구성할 때, 어떠한 칼럼을 인덱스로 걸어야할까? 이 때 등장하는 개념이 카디널리티 다.
카디널리티
집합원의 개수. 해당 컬럼의 중복된 수치. 데이터를 어떤 기준으로 나눴을 때, 그 기준 내에서 분류되는 집합의 수
일반적으로 카디널리티가 높도록 인덱스를 구성해야한다.
- 카디널리티가 낮다.
- 성별, 학년 등 중복이 많이 되는 칼럼
- 카디널리티가 높다.
- 주민등록번호, 계좌번호 등 중복이 없는 유니크한 칼럼
인덱스 칼럼 구성을 성별을 기준으로 하면 여자, 남자 두 개이기 때문에 기준이 적어 인덱스하는 의미가 없을 것이다.
만약 여러개의 칼럼을 인덱스를 구성할 경우 높은 순서에서 낮은 순서로 구성하는 것이 성능이 뛰어나다.
인덱스 단점
- 인덱스를 관리하기 위한 테이블을 따로 만들기 때문에 DB에 약 10%에 해당하는 저장공간이 필요하다.
- 인덱스를 관리하기 위해 추가작업이 필요하다.
- 인덱스를 잘못 사용하는 경우 성능을 오히려 저하시킬 수 있다.
- 조회보다 추가, 수정, 삭제가 많은 연산에 사용할 경우 성능이 저하된다.
JPA 인덱스
JPA 2.1 이후부터 인덱스 기능을 지원한다.
// 사용 예시
@Table(indexes = @Index(name = "i_drink", columnList = "name"))
public class Drink {
@Id
@GeneratedValue
private Long id;
private String name;
...
}
JPA에서는 @Index 어노테이션을 활용하여 인덱스를 사용할 수 있다.
@Target({})
@Retention(RUNTIME)
public @interface Index {
String name() default "";
String columnList();
boolean unique() default false;
}
- name()
- 인덱스에는 이름이 존재해야한다.
- 디폴트 값은 기본 생성자이다.
- columnList()
- 인덱스를 구성할 칼럼리스트를 정의할 수 있다.
- 여러 칼럼을 구성할 경우 다음과 같이 선언할 수 있다.
@Index(name = "example", columnList = "firstName, lastName")- 필수 값이다.
- unique()
- 인덱스가 고유한지 여부를 정의하는 unique 속성이다.
- 고유 인덱스는 인덱싱된 필드가 중복 값을 저장하지 않도록 한다.
- 기본값은 false이다.

인덱스를 설정하면 create index를 통해 인덱스 테이블이 생성된 것을 확인할 수 있다.
인덱스 비교
인덱스 유무에 따른 시간차이 실험
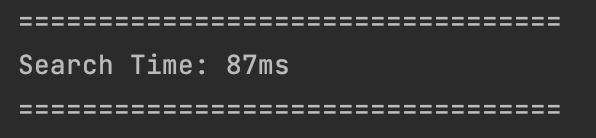
Item 개수가 100개일 경우
인덱스 미사용: 97ms
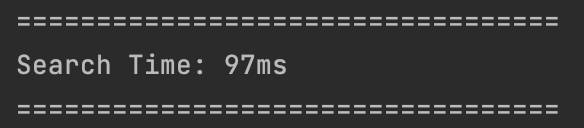
인덱스 사용 : 87ms
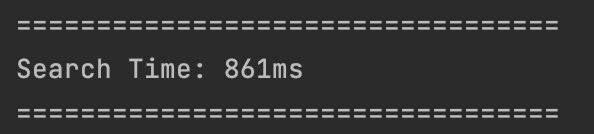
Item 개수가 10000개일 경우
인덱스 미사용: 861ms
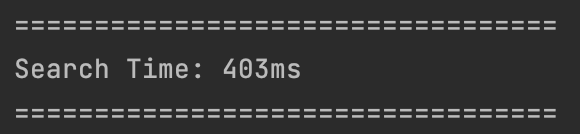
인덱스 사용: 403ms
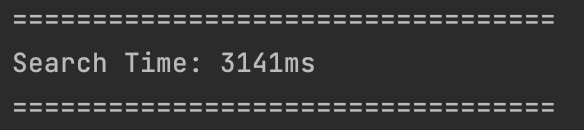
Item 개수가 100000개일 경우
인덱스 미사용: 3141ms
인덱스 사용: 1781ms
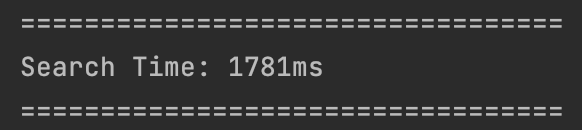
데이터가 많아질수록 점점 성능이 좋아지는 것을 확인할 수 있다.
주절주절 인덱스 적용
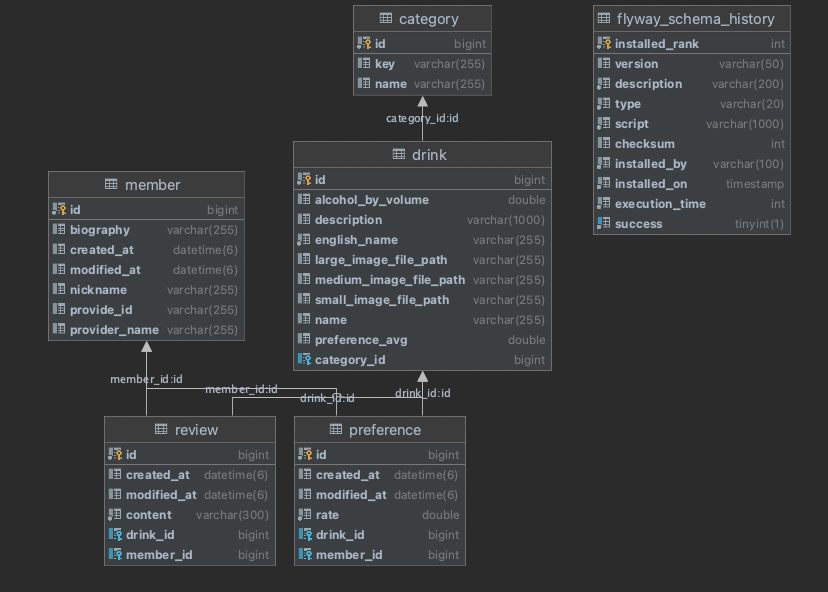
주절주절의 도메인 구조는 위와 같이 되어있다.
인덱스는 조회 시 탐색을 빠르게 해주기 때문에 실제 주절주절에 사용되는 select 쿼리를 기준으로 인덱스를 적용하였다.
Member Table
@Query("select m from Member m where m.provider.provideId = :provideId")
Optional<Member>findByProvideId(String provideId);
@Query("select m from Member m where m.nickname.nickname like :nickname% order by m.createdAt desc")
List<Member>findOneStartingWithNicknameAndMostRecent(String nickname, Pageable pageable);
boolean existsByNicknameNickname(String nickname);
인덱스를 걸만한 칼럼은 where문과 order by문에 걸려있는 provide_id, nickname, createdAt이 있다. 그러나 provide_id는 kakao 하나이기 때문에 잡을 필요가 없다.
따라서 member 테이블에서 생성할 인덱스 테이블은 nickname, createdAt이다.
Member Index
- member -> nickname
- member -> createdAt
create INDEX member_nickname_idx ON member (nickname);
create INDEX member_createdAt_idx ON member (created_at);
Preference Table
Optional<Preference> findByMemberIdAndDrinkId(Long memberId, Long drinkId);
void deleteByMemberIdAndDrinkId(Long memberId, Long drinkId);
@Query("SELECT AVG(p.rate) FROM Preference p WHERE p.drink.id = :drinkId")
Optional<Double> averageOfPreferenceRate(Long drinkId);
@Query("select p from Preference p where p.drink.category.name = :category")
List<Preference> findAllByCategory(String category);
@Query(value = "Select p From Preference p join fetch p.drink d join fetch p.member join fetch d.category where p.member.id = :memberId order by p.createdAt desc",
countQuery = "Select count(p) From Preference p where p.member.id = :memberId")
Page<Preference> findByMemberIdOrderByCreatedAtDesc(Long memberId, Pageable pageable);
mysql DB 기준으로 innodb에서만 외래키에 자동으로 인덱스를 걸어준다고 한다.
Preference Index
- preference -> createdAt
create INDEX preference_createdAt_idx ON preference (created_at);
Review Table
@Query(value = "select r from Review r join fetch r.member where r.drink.id = :drinkId",
countQuery = "select count(r) from Review r where r.drink.id = :drinkId")
Page<Review> findAllByDrinkId(Long drinkId, Pageable pageable);
@Query("select r from Review r where r.drink.id = :drinkId and r.member.id = :memberId order by r.createdAt desc")
List<Review> findByDrinkIdAndMemberId(Long drinkId, Long memberId, Pageable pageable);
@Query(value = "select r from Review r join fetch r.drink d join fetch d.category where r.member.id = :memberId order by r.createdAt desc",
countQuery = "select count(r) from Review r where r.member.id = :memberId")
Page<Review> findReviewsOfMine(Long memberId, Pageable pageable);
Review Index
- review -> createdAt
create INDEX review_createdAt_idx ON review (created_at);
Drink Table
@Query("select d from Drink d join fetch d.category where d.id = :drinkId")
Optional<Drink> findByIdWithFetch(Long drinkId);
@Query("select d from Drink d where d.name.name = :drinkName")
Optional<Drink> findByName(String drinkName);
@Query(value = "select d from Drink d join fetch d.category order by d.preferenceAvg desc")
List<Drink> findDrinks(Pageable pageable);
@Query("select d from Drink d join fetch d.category "
+ "where (d.id in (select p.drink.id from Preference p where p.member.id = :memberId and p.rate > 3) "
+ "or d.id not in (select p.drink.id from Preference p where p.member.id = :memberId)) and d.category.key = :category order by d.preferenceAvg desc")
List<Drink> findDrinksForMember(Long memberId, Pageable pageable, String category);
@Query("select d from Drink d join fetch d.category "
+ "where d.id in (select p.drink.id from Preference p where p.member.id = :memberId and p.rate > 3) "
+ "or d.id not in (select p.drink.id from Preference p where p.member.id = :memberId) order by d.preferenceAvg desc")
List<Drink> findDrinksForMember(Long memberId, Pageable pageable);
@Query(value = "select d from Drink d join fetch d.category c where c.key = :category order by d.preferenceAvg desc"
,countQuery = "select count(d) from Drink d where d.category.key = :category")
Page<Drink> findAllByCategorySorted(String category, Pageable pageable);
@Query(value = "select d from Drink d join fetch d.category c where c.key = :category"
,countQuery = "select count(d) from Drink d where d.category.key = :category")
Page<Drink> findAllByCategory(String category, Pageable pageable);
@Query(value = "select d from Drink d join fetch d.category order by d.preferenceAvg desc",
countQuery = "select count(d) from Drink d")
Page<Drink> findAllSortByPreference(Pageable pageable);
@Query(value = "select d from Drink d where d.name.name like %:keyword% or d.englishName.englishName like %:keyword%")
Page<Drink> findWithKeyword(String keyword, Pageable pageable);
@Query(value = "select d from Drink d join fetch d.category where d.id in :iDs")
List<Drink> findByIds(List<Long> iDs);
선호도 같은 경우 memberId에서 rate의 범위 기준으로 탐색하기 때문에 두 개의 인덱스를 걸어준다.
Drink Index
- drink → drinkName
- drink → preferenceAvg
- preference → (memberId, rate)
create INDEX drink_drinkName_idx ON drink (name);
create INDEX drink_preferenceAvg_idx ON drink (preference_avg);
create INDEX preference_memberId_rate_idx ON preference (member_id, rate);
참고 자료
- https://javaee.github.io/javaee-spec/javadocs/javax/persistence/package-summary.html
- https://helloinyong.tistory.com/296
- https://jojoldu.tistory.com/243
- https://www.baeldung.com/jpa-indexes
- https://d2.naver.com/helloworld/1155
- https://junghn.tistory.com/entry/DB-%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0-%EC%9D%B8%EB%8D%B1%EC%8A%A4%EC%99%80-%EB%84%8C%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0-%EC%9D%B8%EB%8D%B1%EC%8A%A4-%EA%B0%9C%EB%85%90-%EC%B4%9D%EC%A0%95%EB%A6%AC
- https://www.youtube.com/watch?v=P5SZaTQnVCA&t=918s