crontab을 사용해 AWS S3에 데이터 백업하기
on 조잘조잘
로그 백업하기
로그 저장 정책
우리 어플리케이션의 로그는 하루 단위로 저장된다. 날짜가 지나면 전날의 로그를 zip 파일로 저장하며, 30일이 지나면 오래된 파일부터 삭제한다. 이 설정은 Logback을 통해 완료해둔 상황이다.
로그 백업이 필요한 이유는 아래와 같다.
- 로그 관련 리팩토링을 거쳐 기존보다 많은 로그가 생성된다.
- 정식 배포를 마쳤으므로 사용자가 늘면 로그도 더 많이 생성될 것이다.
- 생성되는 로그가 많아질수록 서버에서 많은 메모리를 차지할 것이다. 30일간 저장하는 것에서 더 적은 일자로 바꿔 부담을 줄이고 싶다.
저장소 선정
처음에 생각한 방법은 Logstash + ElasticSearch 를 통한 전송, 저장이다. Logstash가 로그를 수집하면 다양한 형태로 출력할 수 있다. ElasticSearch에 적재해 데이터를 분석, 가공하고 Kibana로 모니터링할 수도 있고, 로그 지표를 AWS CloudWatch로 바로 출력할 수도 있다. 물론 단순 저장 목적으로 사용해도 된다.
하지만 이 방법은
- 저장 목적으로만 사용하기엔 생각 이상으로 리소스가 소요되고,
- 이미 AWS CloudWatch에서 확인하는 로그가 이미 우리 입맛대로 가공된 상황이므로
- Kibana를 적용해서 관리 포인트가 늘어나면 번거로워지기만 할 수 있다고 판단했다.
고로 단순 백업 목적에 더 가까운 방법을 생각하게 되었다.
crontab
crontab
crontab은 cron table을 말한다. cron은 유닉스 계열 운영체제에서 지원하는 시간 기반 잡 스케줄러이다. 고정된 시간, 날짜, 간격에 주기적으로 작업을 실행할 수 있게 해준다. (참고)
crontab 사용
이번 작업을 수행하면서 자주 사용한 대표적인 명령어를 별도로 기재한다.
crontab을 열어 편집
$ crontab -e나는 거의 vim 으로 사용하는데, 우연찮게 다른 컴퓨터에서 작업하다가 nano로 열려 난감했었다. 아래처럼 편집기를 선택할 수 있다.
# nano $ export VISUAL=nano; crontab -e # vim $ export VISUAL=vim; crontab -e그리고 아래 두 명령어는 각각의 crontab을 생성한다. 즉,
sudo로 만든 crontab은 일반 crontab과 공유되지 않는다. 내 경우에 일반 crontab 은 ubuntu 계정으로 실행되는 반면 sudo는 root 계정으로 실행되었다. 참고 에 따르면 기본 설정은 root라는데 차이가 있었다.$ crontab -e $ sudo crontab -e저장된 스케줄 조회
$ crontab -l스케줄은 실행할 날짜와 작업 지정
* * * * * [뭔가 실행할 일]다섯 개의
*로 주기를 설정할 수 있다. 순서대로- 분(0-59)
- 시간(0-23)
- 일(1-31)
- 월(1-12)
요일(0-7)
0, 7은 일요일, 1부터 월요일
을 의미한다.
cron 실행 상태 확인
$ service cron status
crontab 스케줄링
실행중인 우리 AWS EC2 서버에서 crontab -e 를 입력했을 때 등록되어 있는 스케줄이다.

매일 밤 12시 10분에 쉘 스크립트를 실행하도록 작성했다.
미리 만들어 놓은 sh 파일을 실행하며 전송 과정을 별도의 로그로 남긴다. 로그 파일은 매번 생성하지 않고 이어서 작성한다. 처음에는 로그를 생성하지 않고 작업했는데, 실패할 때마다 원인을 몰라서 만들게 되었다. service cron status 로도 한계가 있었다.
실제로 출력된 로그이다.
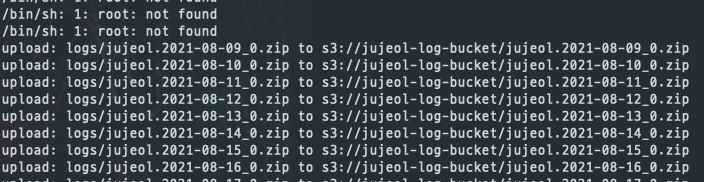
매일 업로드가 성공할 때마다 기록되고 있다.
쉘 스크립트 작성
날짜 설정
쉘 스크립트를 작성하기에 앞서 한 일이 현재 날짜를 입력받도록 한 것이다. 로그 파일은 jujeol.{로그 생성 일자}.zip 형태로 되어있기 때문에 저 로그 생성 일자 부분이 시간이 지남에 따라 동적으로 변할 수 있게 만들어야 한다.
간단하게 오늘 날짜를 출력하고 싶으면
$ YYYYMMDD=`date '+%Y%m%d'`
위와 같이 작성하면 된다. 우리 로그 파일 형식에 맞게 변형을 하고 출력하면 다음과 같은 결과를 확인할 수 있다.
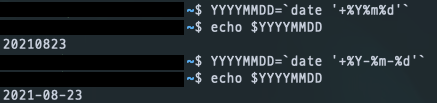
하지만 우리가 확인하고 싶은 날짜는 어제 이기 때문에 다른 설정이 필요하다. 참고 에 따라 아래와 같이 설정한다. 이 설정은 단순히 EC2 배쉬에서 해주는 것이 아니라, 쉘 스크립트 안에 직접 작성해야 한다.
$ YESTERDAY=`TZ=aaa24 date +%Y-%m-%d`
AWS S3로 파일 전송하기
AWS CLI를 먼저 설치 한다. access key가 있다면 /aws/credentials 에 설정 해준다. 우리는 모든 권한 설정에 IAM role 을 부여하는 형식을 이용했다.
$ curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
$ unzip awscliv2.zip # 없다면 apt install upzip 으로 설치한다.
$ sudo ./aws/install
$ aws --version # 설치를 마치고 버전을 확인해본다.
S3 업로드에도 몇 가지 종류가 있다.
aws s3 mv파일을 말 그대로 이동시킨다. S3 버킷으로 이동시킨 뒤 파일은 내 위치에 없고, S3에만 존재하게 된다.
$ sudo aws s3 mv [이동시킬 파일] s3://{S3 버킷 이름 + (폴더)}aws s3 sync내 위치와 S3 버킷의 상태를 똑같이 맞춘다. 폴더 단위로만 작동한다. 여러 파일을 한 번에 옮길 수 있다. S3 버킷 이름만 입력하면 최상위 폴더에 위치하게 된다.
--delete옵션을 주면 없어진 파일은 삭제한다.$ sudo aws s3 sync [싱크를 맞출 폴더] s3://{S3 버킷 이름 + (폴더)} $ sudo aws s3 sync --delete [싱크를 맞출 폴더] s3://{S3 버킷 이름 + 폴더}aws s3 cp파일을 복사한다. 이번 작업에서 우리가 선택한 방법이다.
$ sudo aws s3 cp [복사할 파일] s3://{S3 버킷 이름 + (폴더)}
log-backup.sh
필요한 작업을 모두 넣으면 아래와 같은 형태가 된다.
# cron의 기본설정은 sh이기 때문에 bash로 실행하고 싶다면 이 부분을 추가한다.
SHELL=/bin/bash
# aws 바이너리를 제대로 읽어오지 못할 경우 추가한다.
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
# 여기에 따로 써주지 않으면 안먹힌다.
YESTERDAY=`TZ=aaa24 date +%Y-%m-%d`
sudo aws s3 cp /home/ubuntu/logs/jujeol.$YESTERDAY*.zip s3://jujeol-log-bucket
sh 파일을 실행할 때 계속 Permission denied 에러가 발생한다면,
$ chmod +x log-backup.sh
스크립트 실행 권한을 준다. (참고)
추가사항
추가로 적용하고 싶은 부분
지금은 로그 파일이 보통 한 개 밖에 생성되지 않기 때문에 문제가 없지만, 0, 1, 2, 3, .. 여러 개로 늘어나면 이슈가 생길 것이다. 여러 개의 파일을 cp 명령어로 이동하는 방법을 찾아보거나, 일자별 폴더를 생성하여 sync 로 처리하도록 만들어야 할 것 같다.