협업 필터링
on 조잘조잘
목차
추천 알고리즘
들어가기에 앞서…
이번 우아한테크코스 레벨3을 진행하면서 추천 알고리즘이 필요하게 되었다. 여러 시행착오를 거친 추천 알고리즘 일대기를 적어 내려가고자 한다.
스프링 만지고 싶어
이론 말고 협업 필터링을 구현을 바로 보고싶다면 여기로
추천 알고리즘 종류(CB vs CF)
추천 알고리즘은 대표적으로 CB(Content Based), CF(Collaborative Filtering) 두 가지로 나뉜다. 이외에도 LF(Latent Factorization), Hybrid Filtering 등이 있으나 CB, CF 기반으로 파생된 것이므로 이 글에서는 다루지 않는다.
CB(Content Based)
사용자 혹은 아이템에 대한 프로필 데이터를 가지고 내가 좋아했던 아이템과 비슷한 유형의 아이템을 추천하거나 나와 비슷한 유형의 사람이 좋아하는 아이템을 추천
사용자를 기준으로 하게 되면 사용자의 프로필(성별, 나이, 지역 등)을 미리 받아 이와 비슷한 사용자가 선호하는 상품을 추천해주는 방식이다.
상품을 기준으로 하게 되면 상품의 특징(주종, 도수 등)이 비슷한 상품끼리 묶어 A 상품을 사용자가 좋아하면 A와 비슷한 주류를 추천해주는 방식이다.
만약 우리가 CB를 사용한다면, 주류 상품을 카테고리 또는 도수 등으로 분리하여 사용자가 A 주류를 좋아한다고 하면 해당 주류와 비슷한 주류를 추천해주면 된다.
CB의 단점 또한 존재한다. 해당 주류의 데이터를 일일히 작성해야하는 번거로움이 있고, 이 데이터가 주관적인(맛, 설명) 데이터면 객관성이 떨어진다는 단점이 있다.
CF(Collaborative Filtering)
내가 남긴 평점 데이터를 가지고 나와 취향이 비슷한 사람이 선호하는 아이템을 추천
CF는 프로필 데이터 없이 사용자의 발자취를 통해 추천을 진행한다.
예를 들어, 10명의 사용자들이 각자 자신의 선호도를 입력하게 된다면, 나와 비슷한 선호도를 가진 주류를 추천해주는 방식이다.
CF는 신규 사용자이거나 초기 데이터가 없으면 추천 정확도가 급격히 떨어진다는 단점이 있다. 또한 매우 어렵다. 하지만 일반적으로 CB보다 정확하다고 한다.
CB? or CF?
우리 주절주절에서는 처음 타겟팅 했던 추천 알고리즘은 협업 필터링(CF)이다. 그러나 초기데이터가 없는 것이 큰 문제다. 막상 CB를 적용시키기에도 아직 주류를 분류하는 기준이 주종밖에 없기 때문에 이마저도 어려워 보인다. 그래서 대량의 데이터를 만들던 어떻게든 방법을 찾아 CF를 적용하는 방향으로 가기로 했다. 아마도…?
협업 필터링(Collaborative Filtering)
협업 필터링 동작 방식
아래는 각 크루들이 맥주에 대한 선호도 평가를 내린 것이다.
| 라거 | 에일 | 밀 | 둔켈 | 스타우트 | |
|---|---|---|---|---|---|
| 피카 | 5 | 4 | 4 | 3 | |
| 웨지 | 1 | 0 | 1 | 4 | |
| 나봄 | 4 | 4 | 5 | 3 | |
| 크로플 | 2 | 1 | 4 | 3 | |
| 소롱 | 4 | 4 | 4 | 2 | |
| 서니 | 4 | 2 | 3 | 1 | |
| 티케 | 2 | 4 | 1 | 4 |
사용자 기반(User Based)
사용자 기반의 협업 필터링에서 유사도는 두 사용자가 얼마나 유사한 항목을 선호하는지를 기준으로 한다. 유사도를 구하는 방법에는 코사인 유사도, 피어슨 유사도 를 사용할 수 있다. 이 글에서는 코사인 유사도만 다뤄보기로 한다!
코사인 유사도 를 이용하여 웨지와 크로플의 유사도를 구해보자. 유사도를 구할 때에는 두 사용자가 공통으로 평가한 항목에 대해서만 계산한다.
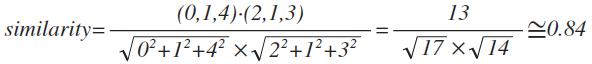
크로플과 웨지의 유사도는 0.84라고 할 수 있다.
이런식으로 모든 사용자에 대해 유사도를 구할 수 있다.
| 피카 | 웨지 | 나봄 | 크로플 | 소롱 | 서니 | 티케 | |
|---|---|---|---|---|---|---|---|
| 피카 | 1 | 0.84 | 0.96 | 0.82 | 0.98 | 0.98 | 0.86 |
| 웨지 | 0.84 | 1 | 0.61 | 0.84 | 0.63 | 0.47 | 0.73 |
| 나봄 | 0.96 | 0.61 | 1 | 0.87 | 0.99 | 0.92 | 0.93 |
| 크로플 | 0.82 | 0.84 | 0.97 | 1.00 | 0.85 | 0.71 | 0.97 |
| 소롱 | 0.98 | 0.63 | 0.99 | 0.85 | 1.00 | 0.98 | 0.72 |
| 서니 | 0.98 | 0.47 | 0.92 | 0.71 | 0.98 | 1.00 | 0.69 |
| 티케 | 0.86 | 0.73 | 0.93 | 0.97 | 0.72 | 0.69 | 1 |
이때 피카의 스타우트 평가 점수를 예측해보자! 우리는 피카와 유사한 몇명의 점수를 이용하여 점수를 구할 수 있고, 전체를 대상으로 예측 점수를 사용할 수도 있다. 전체를 대상으로 하여 평가 점수를 예측해보자.
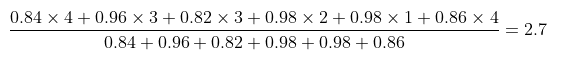
피카의 스타우트 평가 점수는 2.7점으로 예측할 수 있다.
아이템 기반(Item-Based)
아이템 기반 또한 사용자 기반과 매우 유사한 과정을 거친다. 여기에서는 아이템들 간의 유사도를 계산한다. 라거와 에일의 유사도를 구하려고 한다면, 이 둘을 모두 평가한 사용자를 기반으로 계산한다. 각각에 대한 평가는 (5, 1, 4, 4, 2), (4, 0, 4, 2, 4) 이다.
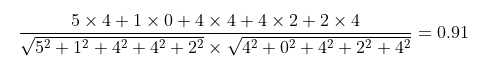
에일과 라거 유사도는 0.91로 다소 높은 유사도를 보인다. 이는 일반적으로 라거를 좋아하면 에일을 좋아하고 에일을 좋아하면 라거를 좋아한다고 말할 수 있다.
우리는 사용자를 기반 으로한 협업 필터링을 적용하고자 한다!
협업 필터링 적용기
우리는 mahout 라이브러리를 사용하여 협업 필터링을 구현하고자 하였다.
파이썬 쪽으로는 추천 시스템 관련 라이브러리가 잘 되어있는데, 우리는 자바를 사용해야했기 때문에 mahout을 이용했다.
mahout 적용은 이 글 을 따라서 적용하였다.
gradle 추가
dependencies {
implementation('org.apache.mahout:mahout-integration:0.13.0') {
exclude group: 'log4j', module: 'log4j'
exclude group: 'org.slf4j', module: 'slf4j-log4j12'
}
'org.apache.mahout:mahout-integration:0.13.0' 을 통해 해당 라이브러리를 추가한다. 스프링 부트의 로그와 mahout 로그가 겹치기 때문에 충돌이 일어나 exclude를 해주었다.
mahout 흐름
// DataModel 읽어들이기
DataModel model = new FileDataModel(new File("data.csv"));
// 유저 기준으로 유사성 계산
UserSimilarity similarity = new PearsonCorrelationSimilarity(model);
// 0.1 보다 큰 유사성을 가진 데이터를 사용
UserNeighborhood neighborhood = new ThresholdUserNeighborhoodl(0.1, similarity, model);
// 유저 기준 추천 모델을 만든다.
UserBasedRecommender recommender = new GenericUserBased(model, neighborhood, similarity);
// 2번 유저에게 1개의 아이템을 추천한다.
List<RecommendedItem> recommendations = recommender.recommend(2, 1);
for (RecommendedItem recoomendation : recommendations) {
System.out.println(recommendation);
}
mahout 라이브러리를 이용한 협업 필터링의 큰 흐름은 다음과 같다.
- DataModel을 만든다.
- 유저 기준(UserSimilarity) 또는 아이템 기준(ItemSimilarity)으로 유사성을 계산한다.
- 유사도 기준으로 데이터를 분류한다.
- 유저 기준(UserBasedRecommender) 또는 아이템 기준(ItemBasedRecommender)로 추천 모델을 만든다.
- 유저가 추천 받을 아이템 개수를 입력한다.
DataModel
Mahout은 다양한 방식으로 데이터 모델을 만들 수 있도록 지원하고 있다.
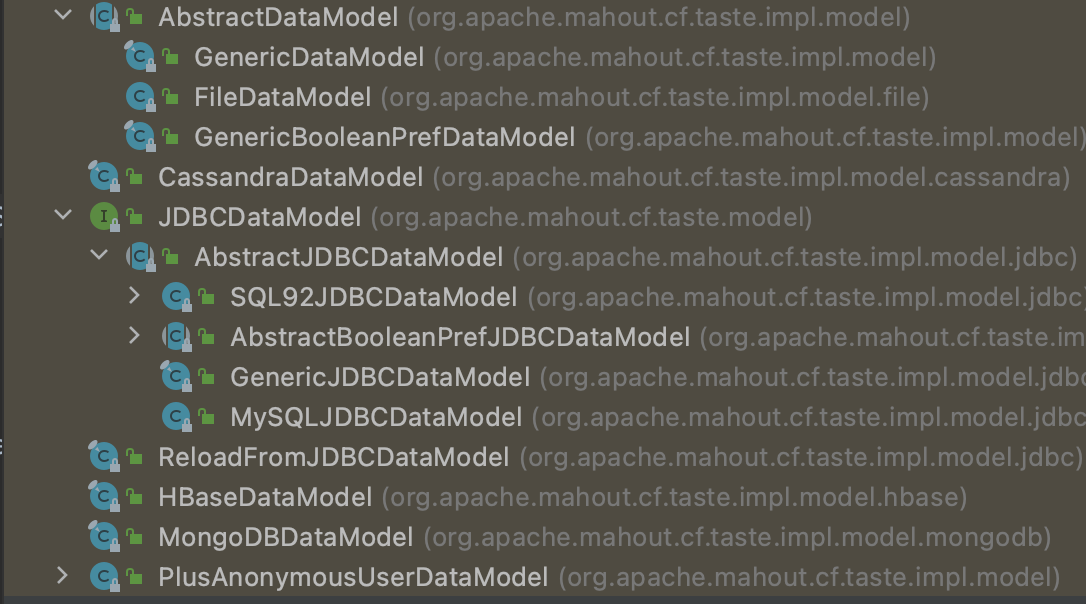
사진에 보이는 것처럼 File을 직접 읽어와 DataModel을 만들 수도 있고, MySQL, MongoDB, H2, JDBC 등 DB에서 읽어와 DataModel을 만들 수 도 있다.
처음에는 local에서는 H2, prod와 dev에서는 MySQL 구현체를 사용하여 데이터 모델을 만들어 주는 방식을 사용했다.
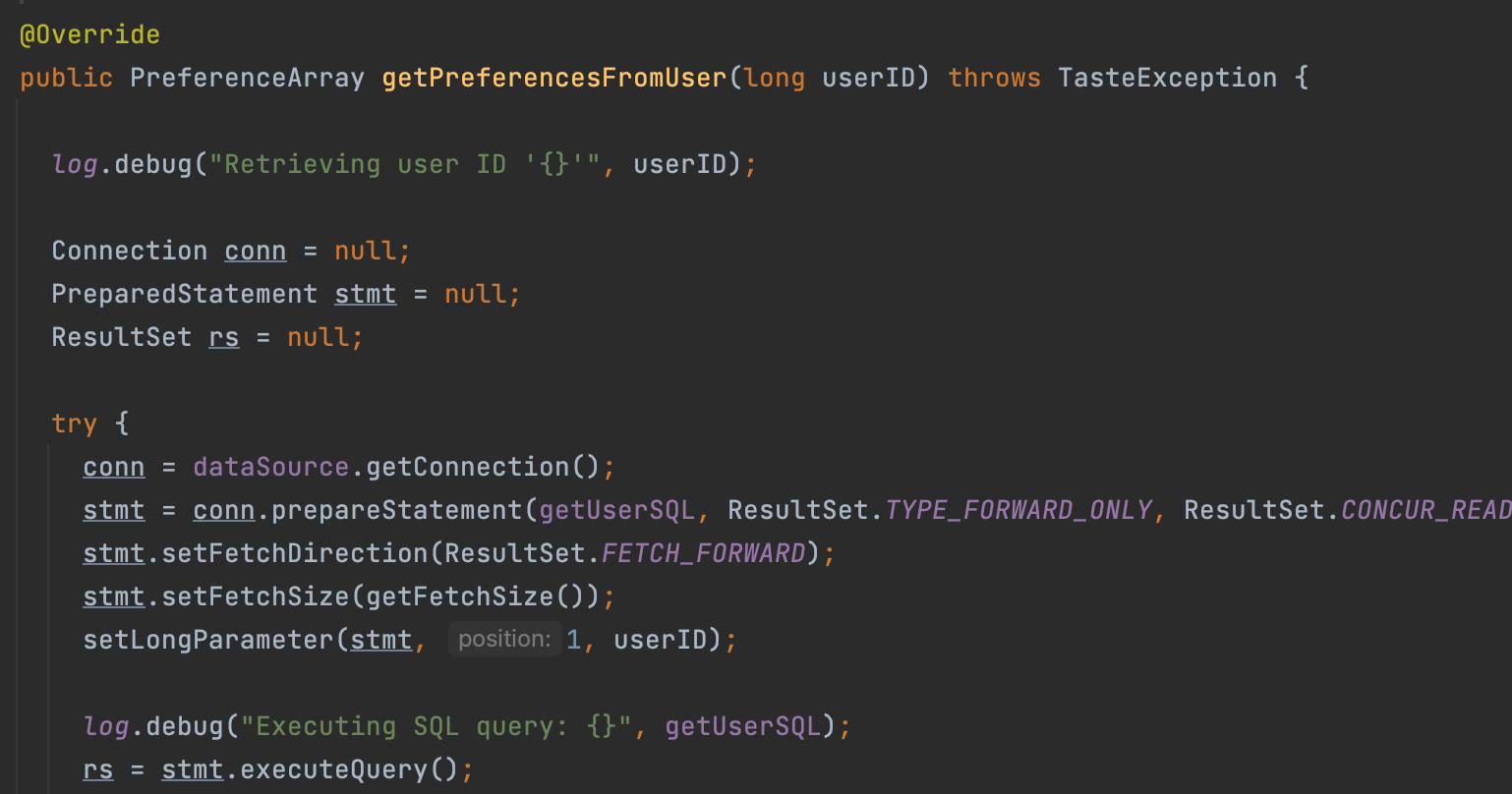
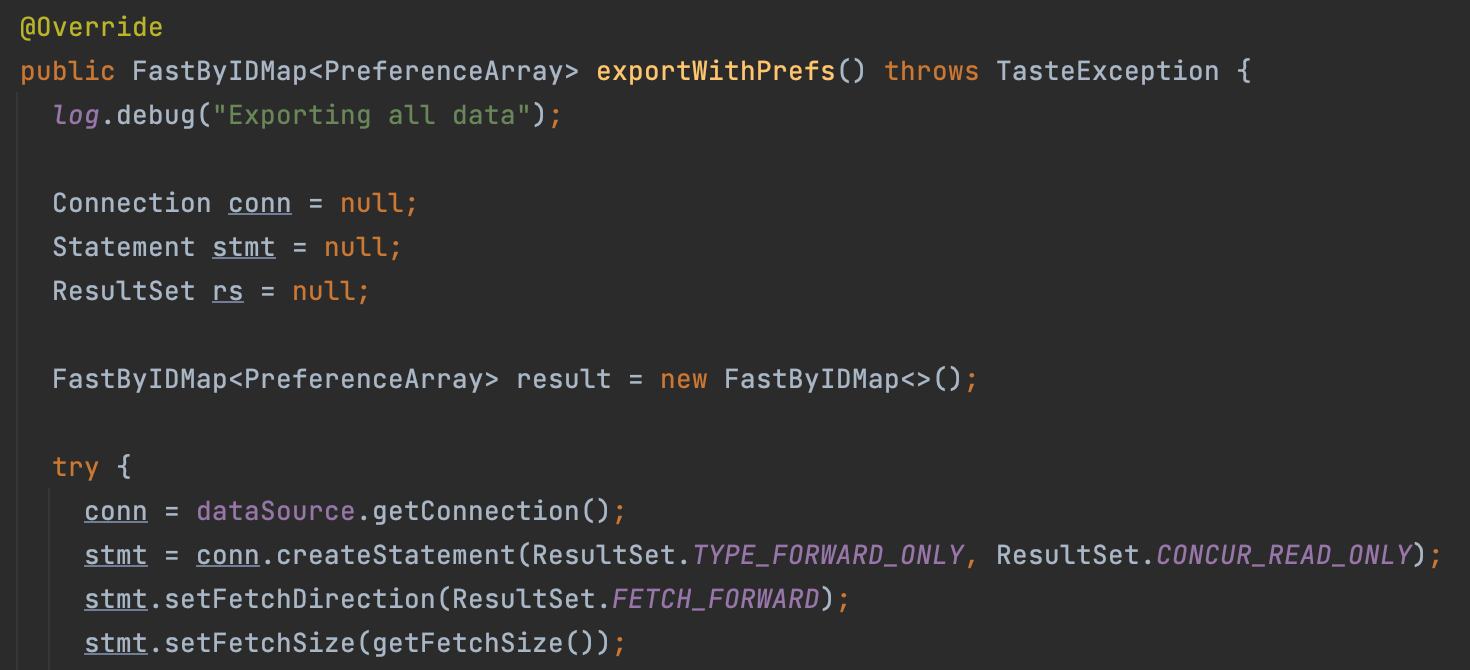
그러나 실제 서버를 돌려보며 DB쪽에 많은 과부하가 걸려 다운되는 현상이 발생하여 협업 알고리즘을 최적화 하는 방식을 찾아보기로 하였다. 실제 내부 구현체를 보니 위의 사진처럼 하나의 메서드에서 데이터가 필요할 때마다 DB Connection을 열고 닫으며 쿼리를 날리고 있었다.
우리는 데이터를 한번만 가져와 필터링하면 되기 때문에 DataSource를 직접 넣어주어 인터페이스를 통해 구현체를 직접 만들어 사용했다. (나봄 구현)
테스트
협업 필터링을 실제로 구현하여 테스트한 결과
// 선호도_등록(주류ID, 선호도, 멤버) 메소드를 통해 선호도를 등록함
private void 협업_필터링_데이터_등록() {
memberAcceptanceTool.선호도_등록(obId, 2.0, PIKA);
memberAcceptanceTool.선호도_등록(stellaId, 5.0, PIKA);
memberAcceptanceTool.선호도_등록(kgbId, 4.5, PIKA);
memberAcceptanceTool.선호도_등록(obId, 1.5, SOLONG);
memberAcceptanceTool.선호도_등록(stellaId, 4.5, SOLONG);
memberAcceptanceTool.선호도_등록(kgbId, 4.2, SOLONG);
memberAcceptanceTool.선호도_등록(tigerId, 5.0, SOLONG);
memberAcceptanceTool.선호도_등록(appleId, 4.5, SOLONG);
memberAcceptanceTool.선호도_등록(tigerRadId, 4.5, SOLONG);
memberAcceptanceTool.선호도_등록(obId, 1.0, WEDGE);
memberAcceptanceTool.선호도_등록(kgbId, 4.5, WEDGE);
memberAcceptanceTool.선호도_등록(stellaId, 5.0, WEDGE);
memberAcceptanceTool.선호도_등록(tigerId, 4.7, WEDGE);
memberAcceptanceTool.선호도_등록(appleId, 4.5, WEDGE);
memberAcceptanceTool.선호도_등록(tigerRadId, 4.5, WEDGE);
memberAcceptanceTool.선호도_등록(obId, 4.7, CROFFLE);
memberAcceptanceTool.선호도_등록(kgbId, 1.5, CROFFLE);
memberAcceptanceTool.선호도_등록(stellaId, 2.4, CROFFLE);
memberAcceptanceTool.선호도_등록(tigerId, 2.1, CROFFLE);
}
현재 피카는 ob에 2점, 스텔라에 5점, kgb에 4.5점을 주었다. 따라서 피카는 ob는 좋아하지 않고, 스텔라와 kgb는 좋아한다는 것을 알 수 있다.
이와 비슷한 취향을 가진 멤버로는 소롱과 웨지가 있고, 반대되는 취향을 가진 멤버는 크로플이 있다.
협업 필터링은 나와 비슷한 사용자가 좋아하는 아이템을 추천해주기때문에 내가 아직 선호도를 체크하지 않았지만, 소롱과 웨지가 좋아하는 tiger, apple, tigerRad 를 추천해줄 것으로 기대된다.
실제 테스트 결과
 실제로 앞서 말한 주류가 제일 상위에 떠있는 것을 확인할 수 있다.
실제로 앞서 말한 주류가 제일 상위에 떠있는 것을 확인할 수 있다.
마무리
실제 주절주절에서 사용된 로직은 앞서 소개한 것보다는 조금 더 복잡해서, 대략적인 큰 흐름만 살펴보았다. 많이 간소시켜 설명한 부분도 있으니 참고해서 읽었으면 좋겠다!
끝으로 협업 필터링은 나봄의 많은 도움으로 이루어졌기 때문에 감사인사를 표한다.
주절주절 화이팅!!
참고 자료
- https://blog.pabii.co.kr/recommendation-algorithm-cb-cf-lf/
- https://yeomko.tistory.com/3
- https://scvgoe.github.io/2017-02-01-%ED%98%91%EC%97%85-%ED%95%84%ED%84%B0%EB%A7%81-%EC%B6%94%EC%B2%9C-%EC%8B%9C%EC%8A%A4%ED%85%9C-(Collaborative-Filtering-Recommendation-System)/
- https://mahout.apache.org/
- https://iamksu.tistory.com/38